
01-初识flask
Flask是Python的一个轻量的Web框架,开发Web应用简单快速。本文就用一个Hello World演示程序和支持增删改查操作的极简博客Web应用来探索Flask的基本用法,以及与之相关的种种技术。
1. 1用到的库和安装方法
1.1.1. flask库
本文的主角,一个轻量的Web框架,安装方式:pip install flask
1.1.2. flask-sqlalchemy库
这是flask的一个数据库ORM(对象关系映射)库,封装了一系列对数据库的操作API,安装方式:pip install flask-sqlalchemy
1.1.3. sqlite
sqlite是一个轻量型的关系型数据库,Python 2.5+版本自带sqlite数据库,不需要额外安装。
1.2. Flask Hello World
将以下代码保存为hello.py并运行:
# coding:utf-8
# Hello World
from __future__ import unicode_literals
from flask import Flask
# 创建应用程序对象
app = Flask(__name__)
@app.route('/')
def hello():
'''
hello请求
'''
# 直接返回字符串
return 'Hello, Flask World!'
if __name__ == '__main__':
# 以debug模式启动程序
app.run(debug = True)打开浏览器,在地址栏输入:http://127.0.0.1:5000/, 可以看到如下页面:

我们的Hello World程序就完成了,因为开启了debug调试模式,所在在命令行中也可以看到发送的请求的日志:

开启debug模式的好处在于,每次对源代码的修改,保存一下刷新页面都可以立即生效,而不用重启程序。
1.3. 一个支持增删改查操作的极简博客MyBlog
下面用flask+sqlalchemy+sqlite来编写一个极简的博客系统,麻雀虽小,五脏俱全,包含增删改查、数据库操作、Jinja2页面模板渲染、HTML表单操作、ajax请求发送等。
1.3.1. 初始化程序和数据库
在一开始,需要做一些初始化的操作,包括初始化app对象和数据库。在当前目录创建一个文件blog.py,在其中写如下代码:
# coding:utf-8
# 一个基于Flask和SQLAlchemy+SQLite的极简博客应用
from __future__ import unicode_literals
from flask import Flask,render_template,redirect,request,url_for
from flask_sqlalchemy import SQLAlchemy
import os
# 创建应用程序对象
app = Flask(__name__)
# 获取当前目录的绝对路径
basedir = os.path.abspath(os.path.dirname(__file__))
# sqlite数据库文件存放路径
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///' + os.path.join(basedir,'app.sqlite')
# 创建数据库对象
db = SQLAlchemy(app)1.3.2. 定义博客文章数据Model类
初始化工作做完之后,下面需要定义一个数据库表的Model类Blog,以完成数据库表和数据对象之间的关系映射:
class Blog(db.Model):
'''
博文数据模型
'''
# 主键ID
id = db.Column(db.Integer,primary_key = True)
# 博文标题
title = db.Column(db.String(100))
# 博文正文
text = db.Column(db.Text)
def __init__(self,title,text):
'''
初始化方法
'''
self.title = title
self.text = text1.3.3. 创建sqlite数据库
在运行程序之前,还需创建sqlite数据库,它以一个文件的形式存放。如果不事先创建数据库,那么在运行程序的时候如果发送涉及数据库操作的请求就会报数据库异常。
打开命令行,切换到blog.py文件所在目录,打开python控制台,执行如下命令来创建sqlite数据库文件、创建数据库表:
from blog import db
db.create_all()注:此操作只需做一次。
1.3.4. 使用模板渲染首页
先定义一个接口,用来接收首页请求:
@app.route('/')
def home():
'''
主页
'''
# 渲染首页HTML模板文件
return render_template('home.html')然后在和blog.py文件同级目录下创建一个名为templates的文件夹,并在其中创建一个home.html文件,内容如下:
<h1>我的博客</h1>
<a href="/blogs">博文列表</a>
<br>
<a href="/blogs/create">去写一篇博客</a>
<br>flask在运行的时候,会去templates目录查找页面模板文件,渲染页面。下面我们运行blog.py,在浏览器中访问http://127.0.0.1:5000,就可以看到首页的效果了:

1.3.5. 博文列表和Jinja2渲染引擎
上述首页中是有一个博文列表的链接的,但是我们还没有实现链接需要跳转到的博文列表页面,下面来实现这个页面。
在blog.py中新增一个请求方法,用于接收查询博文列表的请求:
@app.route('/blogs',methods = ['GET'])
def list_notes():
'''
查询博文列表
'''
blogs = Blog.query.all()
# 渲染博文列表页面目标文件,传入blogs参数
return render_template('list_blogs.html',blogs = blogs)这里返回了一个blogs列表对象,用于在HTML页面中获取并展示博文数据。
然后在templates目录下创建一个list_blogs.html文件,内容如下:
<h3><a href="/">< 回到首页</a></h3>
<h1>博文列表</h1>
<!-- Jinja模板语法 -->
{% if blogs %}
{% for blog in blogs%}
<h3><a href="/blogs/{{blog.id}}">{{blog.title}}</a></h3>
{% endfor %}
{% else %}
<p>还没有一篇博文,去写一篇吧~</p>
<a href="/blogs/create">去写一篇</a>
{% endif %}list_blogs.html中用到了几个模板渲染语法,用来展示后台返回的数据。
在浏览器中访问http://127.0.0.1:5000/blogs,可以看到如下效果:

1.3.6. 博文创建和HTML表单操作
在blog.py中新增一个请求方法,用于接收创建博文的请求,这个方法接收GET和POST两种请求,分别用于渲染创建博文的页面和执行创建博文的操作:
@app.route('/blogs/create',methods = ['GET', 'POST'])
def create_blog():
'''
创建博客文章
'''
if request.method == 'GET':
# 如果是GET请求,则渲染创建页面
return render_template('create_blog.html')
else:
# 从表单请求体中获取请求数据
title = request.form['title']
text = request.form['text']
# 创建一个博文对象
blog = Blog(title = title,text = text)
db.session.add(blog)
# 必须提交才能生效
db.session.commit()
# 创建完成之后重定向到博文列表页面
return redirect('/blogs')然后在templates目录下创建一个create_blog.html文件:
<h1>写博文</h1>
<!-- HTML表单 -->
<form action="/blogs/create" method="POST">
<label>标题:</label>
<input type="text" name="title">
<br><br>
<label>正文:</label>
<input type="text" name="text">
<br><br>
<input type="submit" value="创建">
</form>这里用到了HTML表单,来下发请求数据。
在浏览器中访问http://127.0.0.1:5000/blogs/create进入写博文页面:
填入博文标题和正文,然后点击创建按钮,就跳转到博文列表页面,新创建的博文就显示在列表中了:


1.3.7. 博文详情、删除和ajax请求发送
在blog.py中新增一个方法:
@app.route('/blogs/<id>',methods = ['GET','DELETE'])
def query_note(id):
'''
查询博文详情、删除博文
'''
if request.method == 'GET':
# 到数据库查询博文详情
blog = Blog.query.filter_by(id = id).first_or_404()
# 渲染博文详情页面
return render_template('query_blog.html',blog = blog)
else:
# 删除博文
blog = Blog.query.filter_by(id = id).delete()
# 提交才能生效
db.session.commit()
# 返回204正常响应,否则页面ajax会报错
return '',204在templates目录新增一个query_blog.html文件,用于展示博文详情,和定义删除操作,内容如下:
<h3><a href="/blogs">< 回到博文列表</a></h3>
<h1>博文详情</h1>
<div>
<a href="/blogs/update/{{blog.id}}" id="{{blog.id}}">更新</a>
<h3>{{blog.title}}</h3>
<p>{{blog.text}}</p>
<a href="#" class="btn-delete" id="{{blog.id}}">删除</a>
</div>
<!-- 先引入jquery,下面要用到-->
<script src="https://cdn.bootcss.com/jquery/1.12.4/jquery.min.js"></script>
<!--发送ajax请求删除博文 -->
<script type="text/javascript">
$('a.btn-delete').on('click',function(evt){
// 通知浏览器不要执行与事件关联的默认动作
evt.preventDefault();
// 获取博文ID
var blogid = $(this).attr('id');
$.ajax({
// 请求URL
url: "/blogs/" + blogid,
// 请求方法类型
type: "DELETE",
contentType:"application/json",
// 删除成功响应函数
success:function(resp){
// 在当前页面打开博文列表页面
window.open("/blogs","_self");
},
// 删除失败响应函数
error:function(resp){
// 删除失败,给出错误提示
alert("删除博文失败!详情:" + resp.message);
}
})
});
</script>在这里使用到了jquery的ajax请求来发送删除博文的请求,博文删除成功后,跳转到博文列表页面。
在博文列表页面点击刚刚创建的博文的标题,就跳转到了博文详情页面:

点击删除按钮,博文就被删除了,然后跳转到了博文列表页面:

1.3.8. 博文更新
在blog.py中新增一个请求方法:
@app.route('/blogs/update/<id>',methods = ['GET', 'POST'])
def update_note(id):
'''
更新博文
'''
if request.method == 'GET':
# 根据ID查询博文详情
blog = Blog.query.filter_by(id = id).first_or_404()
# 渲染修改笔记页面HTML模板
return render_template('update_blog.html',blog = blog)
else:
# 获取请求的博文标题和正文
title = request.form['title']
text = request.form['text']
# 更新博文
blog = Blog.query.filter_by(id = id).update({'title':title,'text':text})
# 提交才能生效
db.session.commit()
# 修改完成之后重定向到博文详情页面
return redirect('/blogs/{id}'.format(id = id))在templates目录下新增一个update_blog.html文件,内容如下:
<h1>更新博文</h1>
<!-- HTML表单 -->
<form action="/blogs/update/{{blog.id}}" method="POST">
<label>标题:</label>
<input type="text" name="title" value="{{blog.title}}">
<br><br>
<label>正文:</label>
<input type="text" name="text" value="{{blog.text}}">
<br><br>
<input type="submit" value="提交">
</form>在博文详情页面,点击更新按钮,进入更新博文页面:


更新博文的标题或正文之后,点击提交按钮,更新博文成功,跳转到博文详情页面:

02-flask应用基本结构
2.1 初始化
所有的Flask程序都必须创建一个程序实例, 这个程序实例就是Flask类的对象。客户端把请求发送给Web服务器, 服务器再把请求发送给Flask程序实例, 然后由程序实例处理请求。
创建程序实例:
from flask import Flask
app = Flask(__name__)此处的__name__是一个全局变量, 它的值是代码所处的模块或包的名字, Flask用这个参数决定程序的根目录, 以便稍后能找到相对于程序根目录的资源文件位置。
2.2.路由和视图函数
客户端把请求发送给Web服务器, 服务器再把请求发送给Flask程序实例, 然后由Flask程序实例处理请求。
程序实例如何处理请求, 答案是程序实例通过路由来处理请求——路由就是URL和处理请求的函数的映射——处理请求的函数就叫做视图函数。
Flask定义路由最简便的方式, 是使用程序实例提供的app.route修饰器:
@app.route('/'):
def index():
return '<h1>Hello world!<h1>'前例把index()函数注册为程序根地址的处理程序。 ( 如果部署程序的服务器域名为www.example.com, 在浏览器中访问http://www.example.com后, 会触发服务器执行index()函数。 )
这个函数的返回值称为响应, 是客户端接收到的内容。
地址中包含可变部分的路由:
@app.route('/user/<name>')
def user(name):
return '<h1>Hello, %s!</h1>' %name尖括号中的内容就是动态部分,任何能匹配静态部分的URL都会映射到这个视图函数, 调用视图函数时, Flask会将动态部分作为参数传入函数。
注意:路由中的动态部分默认类型是字符串, 不过也可以使用别的类型如:/user/只会匹配动态片段id为整数的url。
2.3.启动服务器
Flask 应用自带 Web 开发服务器,通过 flask run 命令启动。这个命令在 FLASK_APP 环境变量指定的 Python 脚本中寻找应用实例。
Linux 和 macOS 用户执行下述命令启动 Web 服务器:
(venv) $ export FLASK_APP=app.py
(venv) $ flask run
* Serving Flask app "hello"
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)微软 Windows 用户执行的命令和刚才一样,只不过设定 FLASK_APP 环境变量的方式不同:
(venv) $ set FLASK_APP=app.py
(venv) $ flask run
* Serving Flask app "hello"
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)服务器启动后便开始轮询,处理请求。直到按 Ctrl+C 键停止服务器,轮询才会停止。
服务器运行时,在 Web 浏览器的地址栏中输入 http://localhost:5000/。你看到的页面如图 2-1 所示。

Flask Web 开发服务器也可以通过编程的方式启动:调用 app.run() 方法。
if __name__ == '__main__':
app.run(debug=True) #debug参数为True, 表示启用调试模式。命令行选项
flask 命令支持一些选项。执行 flask --help,或者执行 flask 而不提供任何参数,可以查看哪些选项可用:
(venv) $ flask --help
Usage: flask [OPTIONS] COMMAND [ARGS]...
This shell command acts as general utility script for Flask applications.
It loads the application configured (through the FLASK_APP environment
variable) and then provides commands either provided by the application or
Flask itself.
The most useful commands are the "run" and "shell" command.
Example usage:
$ export FLASK_APP=hello.py
$ export FLASK_DEBUG=1
$ flask run
Options:
--version Show the flask version
--help Show this message and exit.
Commands:
run Runs a development server.
shell Runs a shell in the app context.flask shell 命令在应用的上下文中打开一个 Python shell 会话。在这个会话中可以运行维护任务或测试,也可以调试问题。几章之后将举例说明这个命令的用途。
flask run 命令我们已经用过,从名称可以看出,它的作用是在 Web 开发服务器中运行应用。这个命令有多个参数:
(venv) $ flask run --help
Usage: flask run [OPTIONS]
Runs a local development server for the Flask application.
This local server is recommended for development purposes only but it can
also be used for simple intranet deployments. By default it will not
support any sort of concurrency at all to simplify debugging. This can be
changed with the --with-threads option which will enable basic
multithreading.
The reloader and debugger are by default enabled if the debug flag of
Flask is enabled and disabled otherwise.
Options:
-h, --host TEXT The interface to bind to.
-p, --port INTEGER The port to bind to.
--reload / --no-reload Enable or disable the reloader. By default
the reloader is active if debug is enabled.
--debugger / --no-debugger Enable or disable the debugger. By default
the debugger is active if debug is enabled.
--eager-loading / --lazy-loader
Enable or disable eager loading. By default
eager loading is enabled if the reloader is
disabled.
--with-threads / --without-threads
Enable or disable multithreading.
--help Show this message and exit.--host 参数特别有用,它告诉 Web 服务器在哪个网络接口上监听客户端发来的连接。默认情况下,Flask 的 Web 开发服务器监听 localhost 上的连接,因此服务器只接受运行服务器的计算机发送的连接。下述命令让 Web 服务器监听公共网络接口上的连接,因此同一网络中的其他计算机发送的连接也能接收到:
(venv) $ flask run --host 0.0.0.0
* Serving Flask app "hello"
* Running on http://0.0.0.0:5000/ (Press CTRL+C to quit)现在,网络中的任何计算机都能通过 http://a.b.c.d:5000 访问 Web 服务器。其中,a.b.c.d 是运行服务器的计算机的 IP 地址。
请求–响应循环
应用和请求上下文
Flask 从客户端收到请求时,要让视图函数能访问一些对象,这样才能处理请求。请求对象就是一个很好的例子,它封装了客户端发送的 HTTP 请求。
为了避免大量可有可无的参数把视图函数弄得一团糟,Flask 使用上下文临时把某些对象变为全局可访问。有了上下文,便可以像下面这样编写视图函数:
from flask import request
@app.route('/')
def index():
user_agent = request.headers.get('User-Agent')
return '<p>Your browser is {}</p>'.format(user_agent)请求分派
应用收到客户端发来的请求时,要找到处理该请求的视图函数。为了完成这个任务,Flask 会在应用的 URL 映射中查找请求的 URL。URL 映射是 URL 和视图函数之间的对应关系。Flask 使用 app.route 装饰器构建映射。
要想查看 Flask 应用中的 URL 映射是什么样子,可以在 Python shell 中审查为 app.py 生成的映射。测试之前,请确保你激活了虚拟环境:
(venv) $ python
>>> from app import app
>>> app.url_map
Map([<Rule '/' (HEAD, OPTIONS, GET) -> index>,
<Rule '/static/<filename>' (HEAD, OPTIONS, GET) -> static>,
<Rule '/user/<name>' (HEAD, OPTIONS, GET) -> user>])/ 和 /user/ 路由在应用中使用 app.route 装饰器定义。/static/ 路由是 Flask 添加的特殊路由,用于访问静态文件。
URL 映射中的 (HEAD, OPTIONS, GET) 是请求方法,由路由进行处理。HTTP 规范中规定,每个请求都有对应的处理方法,这通常表示客户端想让服务器执行什么样的操作。Flask 为每个路由都指定了请求方法,这样即使不同的请求方法发送到相同的 URL 上时,也会使用不同的视图函数处理。HEAD 和 OPTIONS 方法由 Flask 自动处理。
响应
Flask 调用视图函数后,会将其返回值作为响应的内容。多数情况下,响应就是一个简单的字符串,作为 HTML 页面回送客户端。
但 HTTP 协议需要的不仅是作为请求响应的字符串。HTTP 响应中一个很重要的部分是状态码,Flask 默认设为 200,表明请求已被成功处理。
如果视图函数返回的响应需要使用不同的状态码,可以把数字代码作为第二个返回值,添加到响应文本之后。例如,下述视图函数返回 400 状态码,表示请求无效:
@app.route('/')
def index():
return '<h1>Bad Request</h1>', 400如果不想返回由 1 个、2 个或 3 个值组成的元组,Flask 视图函数还可以返回一个响应对象。make_response() 函数可接受 1 个、2 个或 3 个参数(和视图函数的返回值一样),然后返回一个等效的响应对象。有时我们需要在视图函数中生成响应对象,然后在响应对象上调用各个方法,进一步设置响应。下例创建一个响应对象,然后设置 cookie:
from flask import make_response
@app.route('/')
def index():
response = make_response('<h1>This document carries a cookie!</h1>')
response.set_cookie('answer', '42')
return response响应有个特殊的类型,称为重定向。这种响应没有页面文档,只会告诉浏览器一个新 URL,用以加载新页面。
重定向的状态码通常是 302,在 Location 首部中提供目标 URL。
from flask import redirect
@app.route('/')
def index():
return redirect('http://www.example.com')还有一种特殊的响应由 abort() 函数生成,用于处理错误。在下面这个例子中,如果 URL 中动态参数 id 对应的用户不存在,就返回状态码 404:
from flask import abort
@app.route('/user/<id>')
def get_user(id):
user = load_user(id)
if not user:
abort(404)
return '<h1>Hello, {}</h1>'.format(user.name)注意,abort() 不会把控制权交还给调用它的函数,而是抛出异常。
03-flask模板
3.1. 模板概述
一. 为什么要使用模板
视图函数有两个作用, 一个是业务逻辑一个是表现逻辑, 举例说明:
用户在网站注册了一个新账号, 用户在表单中输入电子邮件地址和密码, 点击提交按钮, 服务器接收到包含用户输入的请求, 然后Flask把请求分发到处理注册请求的视图函数。 这个视图函数需要访问数据库, 添加新用户(业务逻辑), 然后生成相应回送浏览器(表现逻辑)。
两个完全独立的作用被混淆到一起会使代码难以理解和维护, 所以我们选择把表现逻辑(响应)迁移到模板当中去。
模板是包含响应文本的文件,其中包含用占位变量表示的动态部分,其具体值只在请求的上下文中才能知道。使用真实值替换变量,再返回最终得到的响应字符串,这一过程称为渲染。为了渲染模板,Flask 使用一个名为 Jinja2 的强大模板引擎。
二. 如何使用模板
- 如何渲染模板:
- 模板放在
templates文件夹下 - 从
flask中导入render_template函数。 - 在视图函数中,使用
render_template函数,渲染模板。注意:只需要填写模板的名字,不需要填写templates这个文件夹的路径。
- 模板放在
- 模板传参:
- 如果只有一个或者少量参数,直接在
render_template函数中添加关键字参数就可以了。 - 如果有多个参数的时候,那么可以先把所有的参数放在字典中,然后在
render_template中, 使用两个星号,把字典转换成关键参数传递进去,这样的代码更方便管理和使用。
- 如果只有一个或者少量参数,直接在
- 在模板中,如果要使用一个变量,语法是:``
- 访问模型中的对象属性或者是字典,可以通过
的形式,或者是使用.
示例代码
template01 .py
#encoding: utf-8
from flask import Flask,render_template
app = Flask(__name__)
@app.route('/')
def index():
# 类
class Person(object):
name = u'p17bdw'
age = 18
p = Person()
context = {
'username': u'c17bdw',
'gender': u'男',
'age': 17,
'person': p, # 声明
'websites': {
'baidu': 'www.baidu.com',
'google': 'www.google.com'
}
}
return render_template('anthoer/index.html',**context)
if __name__ == '__main__':
app.run(debug=True)anthoer/index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title></title>
</head>
<body>
这是HTML文件中出现的文字
<p>用户名:{{ username }}</p>
<p>性别:{{ gender }}</p>
<p>年龄:{{ age }}</p>
<hr>
<p>名字:{{ person['name'] }}</p>
<p>年龄:{{ person.age }}</p>
<hr>
<p>百度:{{ websites['baidu'] }}</p>
<p>谷歌:{{ websites['google'] }}</p>
</body>
</html>3.1.1. if判断
- 语法:
- if的使用,可以和python中相差无几。
示例代码
if_statement .py
# 输入 http://127.0.0.1:5000/1/ 为登录状态,否则为未登录状态。
#encoding: utf-8
from flask import Flask,render_template
app = Flask(__name__)
@app.route('/<is_login>/')
def index(is_login):
if is_login == '1':
user = {
'username': u'17bdw',
'age':20
}
return render_template('index.html',user=user)
else:
return render_template('index.html')
if __name__ == '__main__':
app.run(debug=True)index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title></title>
</head>
<body>
{% if user and user.age > 18 %}
<a href="#">{{ user.username }}</a>
<a href="#">注销</a>
{% else %}
<a href="#">登录</a>
<a href="#">注册</a>
{% endif %}
</body>
</html>3.1.2. for循环遍历列表和字典
1. 字典的遍历,语法和`python`一样,可以使用`items()`、`keys()`、`values()`、`iteritems()`、`iterkeys()`、`itervalues()`
`{% for k,v in user.items() %} <p>{{ k }}:{{ v }}</p> {% endfor %}`
2. 列表的遍历:语法和`python`一样。
`{% for website in websites %} <p>{{ website }}</p> {% endfor %}`示例代码
for_statement .py
#encoding: utf-8
from flask import Flask,render_template
app = Flask(__name__)
# for遍历字典
@app.route('/')
def index():
books = [
{
'name': u'西游记',
'author': u'吴承恩',
'price': 109
},
{
'name': u'红楼梦',
'author': u'曹雪芹',
'price': 200
},
{
'name': u'三国演义',
'author': u'罗贯中',
'price': 120
},
{
'name': u'水浒传',
'author': u'施耐庵',
'price': 130
}
]
return render_template('index.html',books=books)
if __name__ == '__main__':
app.run(debug=True)index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<table>
<thead>
<th>书名</th>
<th>作者</th>
<th>价格</th>
</thead>
<tbody>
{% for book in books %}
<tr>
<td>{{ book.name }}</td>
<td>{{ book.author }}</td>
<td>{{ book.price }}</td>
</tr>
{% endfor %}
</tbody>
</table>
</body>
</html>3.1.3. 过滤器
介绍和语法:
- 介绍:过滤器可以处理变量,把原始的变量经过处理后再展示出来。作用的对象是变量。
- 语法:
xxx
default过滤器:如果当前变量不存在,这时候可以指定默认值。
length过滤器:求列表或者字符串或者字典或者元组的长度。
常用的过滤器: abs(value):返回一个数值的绝对值。示例:-1|abs default(value,default_value,boolean=false):如果当前变量没有值,则会使用参数中的值来代替。示例:name|default('xiaotuo')——如果name不存在,则会使用xiaotuo来替代。boolean=False默认是在只有这个变量为undefined的时候才会使用default中的值,如果想使用python的形式判断是否为false,则可以传递boolean=true。也可以使用or来替换。 escape(value)或e:转义字符,会将<、>等符号转义成HTML中的符号。示例:content|escape或content|e。 first(value):返回一个序列的第一个元素。示例:names|first last(value):返回一个序列的最后一个元素。示例:names|last。
length(value):返回一个序列或者字典的长度。示例:names|length。 join(value,d=u''):将一个序列用d这个参数的值拼接成字符串。 safe(value):如果开启了全局转义,那么safe过滤器会将变量关掉转义。示例:content_html|safe。 int(value):将值转换为int类型。 float(value):将值转换为float类型。 lower(value):将字符串转换为小写。 upper(value):将字符串转换为小写。 replace(value,old,new): 替换将old替换为new的字符串。 truncate(value,length=255,killwords=False):截取length长度的字符串。 striptags(value):删除字符串中所有的HTML标签,如果出现多个空格,将替换成一个空格。 trim:截取字符串前面和后面的空白字符。 string(value):将变量转换成字符串。 wordcount(s):计算一个长字符串中单词的个数。
示例代码
filter_demo .py
#encoding: utf-8
from flask import Flask,render_template
app = Flask(__name__)
@app.route('/')
def index():
comments = [
{
'user': u'admin',
'content': 'xxxx'
},
{
'user': u'tesr',
'content': 'xxxx'
}
]
return render_template('index.html',comments=comments)
if __name__ == '__main__':
app.run(debug=True)index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>过滤器</title>
</head>
<body>
# 如果avatar这个变量不存在,就使用default过滤器提供的值
<img src="{{ avatar|default('http://avatar.csdn.net/1/D/B/3_hmzkekek41.jpg') }}" alt="">
<hr>
# length 计算长度
<p>评论数:({{ comments|length }})</p>
<ul>
{% for comment in comments %}
<li>
<a href="#">{{ comment.user }}</a>
<p>{{ comment.content }}</p>
</li>
{% endfor %}
</ul>
</body>
</html>3.1.4. 继承和block
- 继承作用和语法:
- 作用:可以把一些公共的代码放在父模板中,避免每个模板写同样的代码。
- 语法:
`{% extends 'base.html' %}`- block实现:
- 作用:可以让子模板实现一些自己的需求。父模板需要提前定义好。
- 注意点:字模板中的代码,必须放在block块中。
示例代码
app.py
#encoding: utf-8
from flask import Flask,render_template
app = Flask(__name__)
@app.route('/')
def index():
return render_template('index.html')
@app.route('/login/')
def login():
return render_template('login.html')
if __name__ == '__main__':
app.run(debug=True)index.html
{% extends 'base.html' %}
{% block head %}
<style>
</style>
<link rel="stylesheet" href="">
<script></script>
{% endblock %}
{% block title %}
首页
{% endblock %}
{% block main %}
<h1>这是首页</h1>
{% endblock %}base.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>{% block title %}{% endblock %}</title>
<style>
.nav{
background: #3a3a3a;
height: 65px;
}
ul{
overflow: hidden;
}
ul li{
float: left;
list-style: none;
padding: 0 10px;
line-height: 65px;
}
ul li a{
color: #fff;
}
</style>
{% block head %}{% endblock %}
</head>
<body>
<div class="nav">
<ul>
<li><a href="/">首页</a></li>
<li><a href="/login">发布问答</a></li>
</ul>
</div>
{% block main %}{% endblock %}
</body>
</html>login.html
{% extends 'base.html' %}
{% block title %}
登录
{% endblock %}
{% block main %}
<h1>这是登录页面</h1>
{% endblock %}3.2. 使用Flask-Bootstrap集成Bootstrap
Bootstrap 是 Twitter 开发的一个开源 Web 框架,它提供的用户界面组件可用于创建整洁且具有吸引力的网页,而且兼容所有现代的桌面和移动平台 Web 浏览器。
要想在应用中集成 Bootstrap,最直接的方法是根据 Bootstrap 文档中的说明对 HTML 模板进行必要的改动。不过,这个任务使用 Flask 扩展处理要简单得多,而且相关的改动不会导致主逻辑凌乱不堪。
我们要使用的扩展是 Flask-Bootstrap,它可以使用 pip 安装:
(venv) $ pip install flask-bootstrapFlask 扩展在创建应用实例时初始化。
初始化 Flask-Bootstrap。
from flask_bootstrap import Bootstrap
# ...
bootstrap = Bootstrap(app)
@app.route('/user/<name>')
def user(name):
return render_template('user.html', name=name)扩展通常从 flask_<name> 包中导入,其中 <name> 是扩展的名称。多数 Flask 扩展采用两种初始化方式中的一种。在示例中,初始化扩展的方式是把应用实例作为参数传给构造函数。
初始化 Flask-Bootstrap 之后,就可以在应用中使用一个包含所有 Bootstrap 文件和一般结构的基模板。应用利用 Jinja2 的模板继承机制来扩展这个基模板。
templates/user.html:使用 Flask-Bootstrap 的模板
{% extends "bootstrap/base.html" %}
{% block title %}Flasky{% endblock %}
{% block navbar %}
<div class="navbar navbar-inverse" role="navigation">
<div class="container">
<div class="navbar-header">
<button type="button" class="navbar-toggle"
data-toggle="collapse" data-target=".navbar-collapse">
<span class="sr-only">Toggle navigation</span>
<span class="icon-bar"></span>
<span class="icon-bar"></span>
<span class="icon-bar"></span>
</button>
<a class="navbar-brand" href="/">Flasky</a>
</div>
<div class="navbar-collapse collapse">
<ul class="nav navbar-nav">
<li><a href="/">Home</a></li>
</ul>
</div>
</div>
</div>
{% endblock %}
{% block content %}
<div class="container">
<div class="page-header">
<h1>Hello, {{ name }}!</h1>
</div>
</div>
{% endblock %}Jinja2 中的 extends 指令从 Flask-Bootstrap 中导入 bootstrap/base.html,从而实现模板继承。Flask-Bootstrap 的基模板提供了一个网页骨架,引入了 Bootstrap 的所有 CSS 和 JavaScript 文件。
上面这个 user.html 模板定义了 3 个区块,分别名为 title、navbar 和 content。这些区块都是基模板提供的,可在衍生模板中重新定义。title 区块的作用很明显,其中的内容会出现在渲染后的 HTML 文档头部,放在 <title> 标签中。navbar 和 content 这两个区块分别表示页面中的导航栏和主体内容。
在这个模板中,navbar 区块使用 Bootstrap 组件定义了一个简单的导航栏。content 区块中有个 <div> 容器,其中包含一个页头。之前版本中的欢迎消息,现在就放在这个页头里。改动之后的应用如图所示。

3.2.1. url链接
使用url_for(视图函数名称)可以反转成url。
在模板中直接编写简单路由的 URL 链接不难,但对于包含可变部分的动态路由,在模板中构建正确的 URL 就很困难了。而且,直接编写 URL 会对代码中定义的路由产生不必要的依赖关系。如果重新定义路由,模板中的链接可能会失效。
为了避免这些问题,Flask 提供了 url_for() 辅助函数,它使用应用的 URL 映射中保存的信息生成 URL。
url_for() 函数最简单的用法是以视图函数名作为参数,返回对应的 URL。例如,在当前版本的 app.py 应用中调用 url_for('index') 得到的结果是 /,即应用的根 URL。调用 url_for('index', _external=True) 返回的则是绝对地址,在这个示例中是 http://localhost:5000/。
使用 url_for() 生成动态 URL 时,将动态部分作为关键字参数传入。例如,url_for('user', name='john', _external=True) 的返回结果是 http://localhost:5000/user/john。
传给 url_for() 的关键字参数不仅限于动态路由中的参数,非动态的参数也会添加到查询字符串中。例如,url_for('user', name='john', page=2, version=1) 的返回结果是 /user/ john?page=2&version=1。
3.2.2. 加载静态文件
Web 应用不是仅由 Python 代码和模板组成。多数应用还会使用静态文件,例如模板中 HTML 代码引用的图像、JavaScript 源码文件和 CSS。
在前一章中审查 app.py 应用的 URL 映射时,其中有一个 static 路由。这是 Flask 为了支持静态文件而自动添加的,这个特殊路由的 URL 是 /static/。例如,调用 url_for('static', filename='css/styles.css', _external=True) 得到的结果是 http://localhost:5000/static/css/styles.css。
默认设置下,Flask 在应用根目录中名为 static 的子目录中寻找静态文件。如果需要,可在 static 文件夹中使用子文件夹存放文件。服务器收到映射到 static 路由上的 URL 后,生成的响应包含文件系统中对应文件里的内容。
- 语法:
url_for('static',filename='路径') - 可以加载
css文件,可以加载js文件,还有image文件。
第一个:加载css文件
<link rel="stylesheet" href="{{ url_for('static',filename='css/index.css') }}">第二个:加载js文件
<script src="{{ url_for('static',filename='js/index.js') }}"></script>第三个:加载图片文件
<img src="{{ url_for('static',filename='images/zhiliao.png') }}" alt="">04-flask表单
Flask-WTF 扩展可以把处理 Web 表单的过程变成一种愉悦的体验。这个扩展对独立的 WTForms 包进行了包装,方便集成到 Flask 应用中。
Flask-WTF 及其依赖可使用 pip 安装:
pip install flask-wtf4.1. 配置
与其他多数扩展不同,Flask-WTF 无须在应用层初始化,但是它要求应用配置一个密钥。密钥是一个由随机字符构成的唯一字符串,通过加密或签名以不同的方式提升应用的安全性。Flask 使用这个密钥保护用户会话,以防被篡改。
hello.py
app = Flask(__name__)
app.config['SECRET_KEY'] = 'hard to guess string'app.config 字典可用于存储 Flask、扩展和应用自身的配置变量。使用标准的字典句法就能把配置添加到 app.config 对象中。这个对象还提供了一些方法,可以从文件或环境中导入配置。
Flask-WTF 之所以要求应用配置一个密钥,是为了防止表单遭到跨站请求伪造(CSRF,cross-site request forgery)攻击。恶意网站把请求发送到被攻击者已登录的其他网站时,就会引发 CSRF 攻击。Flask-WTF 为所有表单生成安全令牌,存储在用户会话中。
4.2. 表单类
使用 Flask-WTF 时,在服务器端,每个 Web 表单都由一个继承自 FlaskForm 的类表示。这个类定义表单中的一组字段,每个字段都用对象表示。字段对象可附属一个或多个验证函数。验证函数用于验证用户提交的数据是否有效。
示例是一个简单的 Web 表单,包含一个文本字段和一个提交按钮。
hello.py
from flask_wtf import FlaskForm
from wtforms import StringField, SubmitField
from wtforms.validators import DataRequired
class NameForm(FlaskForm):
name = StringField('What is your name?', validators=[DataRequired()])
submit = SubmitField('Submit')这个表单中的字段都定义为类变量,而各个类变量的值是相应字段类型的对象。在这个示例中,NameForm 表单中有一个名为 name 的文本字段和一个名为 submit 的提交按钮。StringField 类表示属性为 type="text" 的 HTML <input> 元素。SubmitField 类表示属性为 type="submit" 的 HTML <input> 元素。字段构造函数的第一个参数是把表单渲染成 HTML 时使用的标注(label)。
StringField 构造函数中的可选参数 validators 指定一个由验证函数组成的列表,在接受用户提交的数据之前验证数据。验证函数 DataRequired() 确保提交的字段内容不为空。
FlaskForm基类由 Flask-WTF 扩展定义,所以要从flask_wtf中导入。然而,字段和验证函数却是直接从 WTForms 包中导入的。
WTForms 支持的 HTML 标准字段如表所示。
表:WTForms支持的HTML标准字段
| 字段类型 | 说明 |
|---|---|
BooleanField | 复选框,值为 True 和 False |
DateField | 文本字段,值为 datetime.date 格式 |
DateTimeField | 文本字段,值为 datetime.datetime 格式 |
DecimalField | 文本字段,值为 decimal.Decimal |
FileField | 文件上传字段 |
HiddenField | 隐藏的文本字段 |
MultipleFileField | 多文件上传字段 |
FieldList | 一组指定类型的字段 |
FloatField | 文本字段,值为浮点数 |
FormField | 把一个表单作为字段嵌入另一个表单 |
IntegerField | 文本字段,值为整数 |
PasswordField | 密码文本字段 |
RadioField | 一组单选按钮 |
SelectField | 下拉列表 |
SelectMultipleField | 下拉列表,可选择多个值 |
SubmitField | 表单提交按钮 |
StringField | 文本字段 |
TextAreaField | 多行文本字段 |
WTForms 内建的验证函数如表所示。
表:WTForms验证函数
| 验证函数 | 说明 |
|---|---|
DataRequired | 确保转换类型后字段中有数据 |
Email | 验证电子邮件地址 |
EqualTo | 比较两个字段的值;常用于要求输入两次密码进行确认的情况 |
InputRequired | 确保转换类型前字段中有数据 |
IPAddress | 验证 IPv4 网络地址 |
Length | 验证输入字符串的长度 |
MacAddress | 验证 MAC 地址 |
NumberRange | 验证输入的值在数字范围之内 |
Optional | 允许字段中没有输入,将跳过其他验证函数 |
Regexp | 使用正则表达式验证输入值 |
URL | 验证 URL |
UUID | 验证 UUID |
AnyOf | 确保输入值在一组可能的值中 |
NoneOf | 确保输入值不在一组可能的值中 |
4.3. 把表单渲染成HTML
表单字段是可调用的,在模板中调用后会渲染成 HTML。假设视图函数通过 form 参数把一个 NameForm 实例传入模板,在模板中可以生成一个简单的 HTML 表单,如下所示:
<form method="POST">
{{ form.hidden_tag() }}
{{ form.name.label }} {{ form.name() }}
{{ form.submit() }}
</form>注意,除了 name 和 submit 字段,这个表单还有个 form.hidden_tag() 元素。这个元素生成一个隐藏的字段,供 Flask-WTF 的 CSRF 防护机制使用。
当然,这种方式渲染出的表单还很简陋。调用字段时传入的任何关键字参数都将转换成字段的 HTML 属性。例如,可以为字段指定 id 或 class 属性,然后为其定义 CSS 样式:
<form method="POST">
{{ form.hidden_tag() }}
{{ form.name.label }} {{ form.name(id='my-text-field') }}
{{ form.submit() }}
</form>即便能指定 HTML 属性,但按照这种方式渲染及美化表单的工作量还是很大,所以在条件允许的情况下,最好使用 Bootstrap 的表单样式。Flask-Bootstrap 扩展提供了一个高层级的辅助函数,可以使用 Bootstrap 预定义的表单样式渲染整个 Flask-WTF 表单,而这些操作只需一次调用即可完成。使用 Flask-Bootstrap,上述表单可以用下面的方式渲染:
{% import "bootstrap/wtf.html" as wtf %}
{{ wtf.quick_form(form) }}import 指令的使用方法和普通 Python 代码一样,通过它可以导入模板元素,在多个模板中使用。导入的 bootstrap/wtf.html 文件中定义了一个使用 Bootstrap 渲染 Flask-WTF 表单对象的辅助函数。wtf.quick_form() 函数的参数为 Flask-WTF 表单对象,使用 Bootstrap 的默认样式渲染传入的表单。hello.py 的完整模板如示例所示。
示例 templates/index.html:使用 Flask-WTF 和 Flask-Bootstrap 渲染表单
{% extends "base.html" %}
{% import "bootstrap/wtf.html" as wtf %}
{% block title %}Flasky{% endblock %}
{% block page_content %}
<div class="page-header">
<h1>Hello, {% if name %}{{ name }}{% else %}Stranger{% endif %}!</h1>
</div>
{{ wtf.quick_form(form) }}
{% endblock %}base.html
{% extends "bootstrap/base.html" %}
{% block title %}Flasky{% endblock %}
{% block navbar %}
<div class="navbar navbar-inverse" role="navigation">
<div class="container">
<div class="navbar-header">
<button type="button" class="navbar-toggle"
data-toggle="collapse" data-target=".navbar-collapse">
<span class="sr-only">Toggle navigation</span>
<span class="icon-bar"></span>
<span class="icon-bar"></span>
<span class="icon-bar"></span>
</button>
<a class="navbar-brand" href="/">Flasky</a>
</div>
<div class="navbar-collapse collapse">
<ul class="nav navbar-nav">
<li><a href="/">Home</a></li>
</ul>
</div>
</div>
</div>
{% endblock %}
{% block content %}
<div class="container">
{% block page_content %}{% endblock %}
</div>
{% endblock %}4.4. 在视图函数中处理表单
在新版 hello.py 中,视图函数 index() 有两个任务:一是渲染表单,二是接收用户在表单中填写的数据。以下示例是更新后的 index() 视图函数。
示例 hello.py:使用 GET 和 POST 请求方法处理 Web 表单
@app.route('/', methods=['GET', 'POST'])
def index():
name = None
form = NameForm()
if form.validate_on_submit():
name = form.name.data
form.name.data = ''
return render_template('index.html', form=form, name=name)app.route 装饰器中多出的 methods 参数告诉 Flask,在 URL 映射中把这个视图函数注册为 GET 和 POST 请求的处理程序。如果没指定 methods 参数,则只把视图函数注册为 GET 请求的处理程序。
这里有必要把 POST 加入方法列表,因为更常使用 POST 请求处理表单提交。表单也可以通过 GET 请求提交,但是 GET 请求没有主体,提交的数据以查询字符串的形式附加到 URL 中,在浏览器的地址栏中可见。基于这个以及其他多个原因,处理表单提交几乎都使用 POST 请求。
图1 是用户首次访问网站时浏览器显示的表单。用户提交名字后,应用会生成一个针对该用户的欢迎消息。欢迎消息下方还是会显示这个表单,以便用户输入新名字。图 2 显示了此时应用的样子。

图1:Flask-WTF Web 表单

图2:提交后显示的 Web 表单
如果用户提交表单之前没有输入名字,那么 DataRequired() 验证函数会捕获这个错误,如图3 所示。注意这个扩展自动提供了多少功能。这说明,像 Flask-WTF 和 Flask-Bootstrap 这样设计良好的扩展能给应用提供十分强大的功能。

图3:验证失败后显示的 Web 表单
05-flask数据库
5.1使用Flask-SQLAlchemy管理数据库
Flask-SQLAlchemy 是一个 Flask 扩展,简化了在 Flask 应用中使用 SQLAlchemy 的操作。SQLAlchemy 是一个强大的关系型数据库框架,支持多种数据库后台。SQLAlchemy 提供了高层 ORM,也提供了使用数据库原生 SQL 的低层功能。
与其他多数扩展一样,Flask-SQLAlchemy 也使用 pip 安装:
(venv) $ pip install flask-sqlalchemy在 Flask-SQLAlchemy 中,数据库使用 URL 指定。几种最流行的数据库引擎使用的 URL 格式如表 1 所示。
表1:FLask-SQLAlchemy数据库URL
| 数据库引擎 | URL |
|---|---|
| MySQL | mysql://username:password@hostname/database |
| Postgres | postgresql://username:password@hostname/database |
| SQLite(Linux,macOS) | sqlite:////absolute/path/to/database |
| SQLite(Windows) | sqlite:///c:/absolute/path/to/database |
在这些 URL 中,hostname 表示数据库服务所在的主机,可以是本地主机(localhost),也可以是远程服务器。数据库服务器上可以托管多个数据库,因此 database 表示要使用的数据库名。如果数据库需要验证身份,使用 username 和 password 提供数据库用户的凭据。
SQLite 数据库没有服务器,因此不用指定 hostname、username 和 password。URL 中的 database 是磁盘中的文件名。
应用使用的数据库 URL 必须保存到 Flask 配置对象的 SQLALCHEMY_DATABASE_URI 键中。Flask-SQLAlchemy 文档还建议把 SQLALCHEMY_TRACK_MODIFICATIONS 键设为 False,以便在不需要跟踪对象变化时降低内存消耗。其他配置选项的作用参阅 Flask-SQLAlchemy 的文档。示例 1 展示如何初始化及配置一个简单的 SQLite 数据库。
示例 1 hello.py:配置数据库
import os
from flask_sqlalchemy import SQLAlchemy
basedir = os.path.abspath(os.path.dirname(__file__))
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] =\
'sqlite:///' + os.path.join(basedir, 'data.sqlite')
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
db = SQLAlchemy(app)db 对象是 SQLAlchemy 类的实例,表示应用使用的数据库,通过它可获得 Flask-SQLAlchemy 提供的所有功能。
5.2. 定义模型
模型这个术语表示应用使用的持久化实体。在 ORM 中,模型一般是一个 Python 类,类中的属性对应于数据库表中的列。 
Flask-SQLAlchemy 创建的数据库实例为模型提供了一个基类以及一系列辅助类和辅助函数,可用于定义模型的结构。图中的 roles 表和 users 表可像示例 2 那样,定义为 Role 和 User 模型。
示例 2 hello.py:定义
Role和User模型
class Role(db.Model):
__tablename__ = 'roles'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(64), unique=True)
def __repr__(self):
return '<Role %r>' % self.name
class User(db.Model):
__tablename__ = 'users'
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(64), unique=True, index=True)
def __repr__(self):
return '<User %r>' % self.username类变量 __tablename__ 定义在数据库中使用的表名。如果没有定义 __tablename__ ,Flask-SQLAlchemy 会使用一个默认名称,但默认的表名没有遵守流行的使用复数命名的约定,所以最好由我们自己来指定表名。其余的类变量都是该模型的属性,定义为 db.Column 类的实例。
db.Column 类构造函数的第一个参数是数据库列和模型属性的类型。表 2 列出了一些可用的列类型以及在模型中使用的 Python 类型。
表2:最常用的SQLAlchemy列类型
| 类型名 | Python类型 | 说明 |
|---|---|---|
Integer | int | 普通整数,通常是 32 位 |
SmallInteger | int | 取值范围小的整数,通常是 16 位 |
BigInteger | int 或 long | 不限制精度的整数 |
Float | float | 浮点数 |
Numeric | decimal.Decimal | 定点数 |
String | str | 变长字符串 |
Text | str | 变长字符串,对较长或不限长度的字符串做了优化 |
Unicode | unicode | 变长 Unicode 字符串 |
UnicodeText | unicode | 变长 Unicode 字符串,对较长或不限长度的字符串做了优化 |
Boolean | bool | 布尔值 |
Date | datetime.date | 日期 |
Time | datetime.time | 时间 |
DateTime | datetime.datetime | 日期和时间 |
Interval | datetime.timedelta | 时间间隔 |
Enum | str | 一组字符串 |
PickleType | 任何 Python 对象 | 自动使用 Pickle 序列化 |
LargeBinary | str | 二进制 blob |
db.Column 的其余参数指定属性的配置选项。表 3 列出了一些可用选项。
表3:最常用的SQLAlchemy列选项
| 选项名 | 说明 |
|---|---|
primary_key | 如果设为 True,列为表的主键 |
unique | 如果设为 True,列不允许出现重复的值 |
index | 如果设为 True,为列创建索引,提升查询效率 |
nullable | 如果设为 True,列允许使用空值;如果设为 False,列不允许使用空值 |
default | 为列定义默认值 |
Flask-SQLAlchemy 要求每个模型都定义主键,这一列经常命名为
id。
虽然没有强制要求,但这两个模型都定义了 __repr()__ 方法,返回一个具有可读性的字符串表示模型,供调试和测试时使用。
5.3. 关系
关系型数据库使用关系把不同表中的行联系起来。上图所示的关系图表示用户和角色之间的一种简单关系。这是角色到用户的一对多关系,因为一个角色可属于多个用户,而每个用户都只能有一个角色。
图中的一对多关系在模型类中的表示方法如示例3 所示。
示例3 hello.py:在数据库模型中定义关系
class Role(db.Model):
# ...
users = db.relationship('User', backref='role')
class User(db.Model):
# ...
role_id = db.Column(db.Integer, db.ForeignKey('roles.id'))如上图所示,关系使用 users 表中的外键连接两行。添加到 User 模型中的 role_id 列被定义为外键,就是这个外键建立起了关系。传给 db.ForeignKey() 的参数 'roles.id' 表明,这列的值是 roles 表中相应行的 id 值。
从“一”那一端可见,添加到 Role 模型中的 users 属性代表这个关系的面向对象视角。对于一个 Role 类的实例,其 users 属性将返回与角色相关联的用户组成的列表(即“多”那一端)。db.relationship() 的第一个参数表明这个关系的另一端是哪个模型。如果关联的模型类在模块后面定义,可使用字符串形式指定。
db.relationship() 中的 backref 参数向 User 模型中添加一个 role 属性,从而定义反向关系。通过 User 实例的这个属性可以获取对应的 Role 模型对象,而不用再通过 role_id 外键获取。
多数情况下,db.relationship() 都能自行找到关系中的外键,但有时却无法确定哪一列是外键。例如,如果 User 模型中有两个或以上的列定义为 Role 模型的外键,SQLAlchemy 就不知道该使用哪一列。如果无法确定外键,就要为 db.relationship()提供额外的参数。表 4 列出了定义关系时常用的配置选项。
表4:常用的SQLAlchemy关系选项
| 选项名 | 说明 |
|---|---|
backref | 在关系的另一个模型中添加反向引用 |
primaryjoin | 明确指定两个模型之间使用的联结条件;只在模棱两可的关系中需要指定 |
lazy | 指定如何加载相关记录,可选值有 select(首次访问时按需加载)、immediate(源对象加载后就加载)、joined(加载记录,但使用联结)、subquery(立即加载,但使用子查询),noload(永不加载)和 dynamic(不加载记录,但提供加载记录的查询) |
uselist | 如果设为 False,不使用列表,而使用标量值 |
order_by | 指定关系中记录的排序方式 |
secondary | 指定多对多关系中关联表的名称 |
secondaryjoin | SQLAlchemy 无法自行决定时,指定多对多关系中的二级联结条件 |
5.4. 数据库操作
现在模型已经按照上图所示的数据库关系图完成配置,可以随时使用了。学习使用模型的最好方法是在 Python shell 中实际操作。接下来的几节将介绍最常用的数据库操作。shell 使用 flask shell 命令启动。不过在执行这个命令之前,要把 FLASK_APP 环境变量设为 hello.py。
5.4.1. 创建表
首先,要让 Flask-SQLAlchemy 根据模型类创建数据库。db.create_all() 函数将寻找所有 db.Model 的子类,然后在数据库中创建对应的表:
(venv) $ flask shell
>>> from hello import db
>>> db.create_all()现在查看应用目录,你会发现有个名为 data.sqlite 的文件,文件名与配置中指定的一样。如果数据库表已经存在于数据库中,那么 db.create_all() 不会重新创建或者更新相应的表。如果修改模型后要把改动应用到现有的数据库中,这一行为会带来不便。更新现有数据库表的蛮力方式是先删除旧表再重新创建:
>>> db.drop_all()
>>> db.create_all()遗憾的是,这个方法有个我们不想看到的副作用,它把数据库中原有的数据都销毁了。本章末尾将介绍一种更好的数据库更新方式。
5.4.2. 插入行
下面这段代码创建一些角色和用户:
>>> from hello import Role, User
>>> admin_role = Role(name='Admin')
>>> mod_role = Role(name='Moderator')
>>> user_role = Role(name='User')
>>> user_john = User(username='john', role=admin_role)
>>> user_susan = User(username='susan', role=user_role)
>>> user_david = User(username='david', role=user_role)模型的构造函数接受的参数是使用关键字参数指定的模型属性初始值。注意,role 属性也可使用,虽然它不是真正的数据库列,但却是一对多关系的高级表示。新建对象时没有明确设定 id 属性,因为在多数数据库中主键由数据库自身管理。现在这些对象只存在于 Python 中,还未写入数据库。因此,id 尚未赋值:
>>> print(admin_role.id)
None
>>> print(mod_role.id)
None
>>> print(user_role.id)
None对数据库的改动通过数据库会话管理,在 Flask-SQLAlchemy 中,会话由 db.session 表示。准备把对象写入数据库之前,要先将其添加到会话中:
>>> db.session.add(admin_role)
>>> db.session.add(mod_role)
>>> db.session.add(user_role)
>>> db.session.add(user_john)
>>> db.session.add(user_susan)
>>> db.session.add(user_david)或者简写成:
>>> db.session.add_all([admin_role, mod_role, user_role,
... user_john, user_susan, user_david])为了把对象写入数据库,我们要调用 commit() 方法提交会话:
>>> db.session.commit()提交数据后再查看 id 属性,现在它们已经赋值了:
>>> print(admin_role.id)
1
>>> print(mod_role.id)
2
>>> print(user_role.id)
3数据库会话能保证数据库的一致性。提交操作使用原子方式把会话中的对象全部写入数据库。如果在写入会话的过程中发生了错误,那么整个会话都会失效。如果你始终把相关改动放在会话中提交,就能避免因部分更新导致的数据库不一致。
5.4.3. 修改行
在数据库会话上调用 add() 方法也能更新模型。我们继续在之前的 shell 会话中进行操作,下面这个例子把 "Admin" 角色重命名为 "Administrator":
>>> admin_role.name = 'Administrator'
>>> db.session.add(admin_role)
>>> db.session.commit()5.4.4. 删除行
数据库会话还有个 delete() 方法。下面这个例子把 "Moderator" 角色从数据库中删除:
>>> db.session.delete(mod_role)
>>> db.session.commit()注意,删除与插入和更新一样,提交数据库会话后才会执行。
5.4.5. 查询行
Flask-SQLAlchemy 为每个模型类都提供了 query 对象。最基本的模型查询是使用 all() 方法取回对应表中的所有记录:
>>> Role.query.all()
[<Role 'Administrator'>, <Role 'User'>]
>>> User.query.all()
[<User 'john'>, <User 'susan'>, <User 'david'>]使用过滤器可以配置 query 对象进行更精确的数据库查询。下面这个例子查找角色为 "User" 的所有用户:
>>> User.query.filter_by(role=user_role).all()
[<User 'susan'>, <User 'david'>]若想查看 SQLAlchemy 为查询生成的原生 SQL 查询语句,只需把 query 对象转换成字符串:
>>> str(User.query.filter_by(role=user_role))
'SELECT users.id AS users_id, users.username AS users_username,
users.role_id AS users_role_id \nFROM users \nWHERE :param_1 = users.role_id'如果你退出了 shell 会话,前面这些例子中创建的对象就不会以 Python 对象的形式存在,但在数据库表中仍有对应的行。如果打开一个新的 shell 会话,要从数据库中读取行,重新创建 Python 对象。下面这个例子发起一个查询,加载名为 "User" 的用户角色:
>>> user_role = Role.query.filter_by(name='User').first()注意,这里发起查询的不是 all() 方法,而是 first() 方法。all() 方法返回所有结果构成的列表,而 first() 方法只返回第一个结果,如果没有结果的话,则返回 None。因此,如果知道查询最多返回一个结果,就可以用这个方法。
filter_by() 等过滤器在 query 对象上调用,返回一个更精确的 query 对象。多个过滤器可以一起调用,直到获得所需结果。
表 5 列出了可在 query 对象上调用的常用过滤器。完整的列表参见 SQLAlchemy 文档(http://docs.sqlalchemy.org)。
表5:常用的SQLAlchemy查询过滤器
| 过滤器 | 说明 |
|---|---|
filter() | 把过滤器添加到原查询上,返回一个新查询 |
filter_by() | 把等值过滤器添加到原查询上,返回一个新查询 |
limit() | 使用指定的值限制原查询返回的结果数量,返回一个新查询 |
offset() | 偏移原查询返回的结果,返回一个新查询 |
order_by() | 根据指定条件对原查询结果进行排序,返回一个新查询 |
group_by() | 根据指定条件对原查询结果进行分组,返回一个新查询 |
在查询上应用指定的过滤器后,调用 all() 方法将执行查询,以列表的形式返回结果。除了 all() 方法之外,还有其他方法能触发查询执行。表6 列出了执行查询的其他方法。
表6:最常用的SQLAlchemy查询执行方法
| 方法 | 说明 |
|---|---|
all() | 以列表形式返回查询的所有结果 |
first() | 返回查询的第一个结果,如果没有结果,则返回 None |
first_or_404() | 返回查询的第一个结果,如果没有结果,则终止请求,返回 404 错误响应 |
get() | 返回指定主键对应的行,如果没有对应的行,则返回 None |
get_or_404() | 返回指定主键对应的行,如果没找到指定的主键,则终止请求,返回 404 错误响应 |
count() | 返回查询结果的数量 |
paginate() | 返回一个 Paginate 对象,包含指定范围内的结果 |
关系与查询的处理方式类似。下面这个例子分别从关系的两端查询角色和用户之间的一对多关系:
>>> users = user_role.users
>>> users
[<User 'susan'>, <User 'david'>]
>>> users[0].role
<Role 'User'>这个例子中的 user_role.users 查询有个小问题。执行 user_role.users 表达式时,隐式的查询会调用 all() 方法,返回一个用户列表。此时,query 对象是隐藏的,无法指定更精确的查询过滤器。就这个示例而言,返回一个按照字母顺序排列的用户列表可能更好。在示例4 中,我们修改了关系的设置,加入了 lazy='dynamic' 参数,从而禁止自动执行查询。
示例4 hello.py:动态数据库关系
class Role(db.Model):
# ...
users = db.relationship('User', backref='role', lazy='dynamic')
# ...这样配置关系之后,user_role.users 将返回一个尚未执行的查询,因此可以在其上添加过滤器:
>>> user_role.users.order_by(User.username).all()
[<User 'david'>, <User 'susan'>]
>>> user_role.users.count()
25.5. 在视图函数中操作数据库
前一节介绍的数据库操作可以直接在视图函数中进行。示例 5 是首页路由的新版本,把用户输入的名字记录到数据库中。
示例 5 hello.py:在视图函数中操作数据库
@app.route('/', methods=['GET', 'POST'])
def index():
form = NameForm()
if form.validate_on_submit():
user = User.query.filter_by(username=form.name.data).first()
if user is None:
user = User(username=form.name.data)
db.session.add(user)
db.session.commit()
session['known'] = False
else:
session['known'] = True
session['name'] = form.name.data
form.name.data = ''
return redirect(url_for('index'))
return render_template('index.html',
form=form, name=session.get('name'),
known=session.get('known', False))在这个修改后的版本中,提交表单后,应用会使用 filter_by() 查询过滤器在数据库中查找提交的名字。变量 known 被写入用户会话中,因此重定向之后,可以把数据传给模板,用于显示自定义的欢迎消息。注意,为了让应用正常运行,必须按照前面介绍的方法,在 Python shell 中创建数据库表。
对应的模板新版本如示例 6 所示。这个模板使用 known 参数在欢迎消息中加入了第二行,从而对已知用户和新用户显示不同的内容。
示例 6 templates/index.html:在模板中定制欢迎消息
{% extends "base.html" %}
{% import "bootstrap/wtf.html" as wtf %}
{% block title %}Flasky{% endblock %}
{% block page_content %}
<div class="page-header">
<h1>Hello, {% if name %}{{ name }}{% else %}Stranger{% endif %}!</h1>
{% if not known %}
<p>Pleased to meet you!</p>
{% else %}
<p>Happy to see you again!</p>
{% endif %}
</div>
{{ wtf.quick_form(form) }}
{% endblock %}5.6. 集成Python shell
每次启动 shell 会话都要导入数据库实例和模型,这真是份枯燥的工作。为了避免一直重复导入,我们可以做些配置,让 flask shell 命令自动导入这些对象。
若想把对象添加到导入列表中,必须使用 app.shell_context_processor 装饰器创建并注册一个 shell 上下文处理器,如示例7 所示。
示例 7 hello.py:添加一个 shell 上下文
@app.shell_context_processor
def make_shell_context():
return dict(db=db, User=User, Role=Role)这个 shell 上下文处理器函数返回一个字典,包含数据库实例和模型。除了默认导入的 app 之外,flask shell 命令将自动把这些对象导入 shell。
$ flask shell
>>> app
<Flask 'hello'>
>>> db
<SQLAlchemy engine='sqlite:////home/flask/flasky/data.sqlite'>
>>> User
<class 'hello.User'>5.7. 使用Flask-Migrate实现数据库迁移
在开发应用的过程中,你会发现有时需要修改数据库模型,而且修改之后还要更新数据库。仅当数据库表不存在时,Flask-SQLAlchemy 才会根据模型创建。因此,更新表的唯一方式就是先删除旧表,但是这样做会丢失数据库中的全部数据。
更新表更好的方法是使用数据库迁移框架。源码版本控制工具可以跟踪源码文件的变化;类似地,数据库迁移框架能跟踪数据库模式的变化,然后以增量的方式把变化应用到数据库中。
SQLAlchemy 的开发人员编写了一个迁移框架,名为 Alembic。除了直接使用 Alembic 之外,Flask 应用还可使用 Flask-Migrate 扩展。这个扩展是对 Alembic 的轻量级包装,并与 flask 命令做了集成。
5.7.1. 创建迁移仓库
首先,要在虚拟环境中安装 Flask-Migrate:
(venv) $ pip install flask-migrate这个扩展的初始化方法如示例 8 所示。
示例 8 hello.py:初始化 Flask-Migrate
from flask_migrate import Migrate
# ...
migrate = Migrate(app, db)为了开放数据库迁移相关的命令,Flask-Migrate 添加了 flask db 命令和几个子命令。在新项目中可以使用 init 子命令添加数据库迁移支持:
(venv) $ flask db init
Creating directory /home/flask/flasky/migrations...done
Creating directory /home/flask/flasky/migrations/versions...done
Generating /home/flask/flasky/migrations/alembic.ini...done
Generating /home/flask/flasky/migrations/env.py...done
Generating /home/flask/flasky/migrations/env.pyc...done
Generating /home/flask/flasky/migrations/README...done
Generating /home/flask/flasky/migrations/script.py.mako...done
Please edit configuration/connection/logging settings in
'/home/flask/flasky/migrations/alembic.ini' before proceeding.这个命令会创建 migrations 目录,所有迁移脚本都存放在这里。
5.7.2. 创建迁移脚本
在 Alembic 中,数据库迁移用迁移脚本表示。脚本中有两个函数,分别是 upgrade() 和 downgrade()。upgrade() 函数把迁移中的改动应用到数据库中,downgrade() 函数则将改动删除。Alembic 具有添加和删除改动的能力,意味着数据库可重设到修改历史的任意一点。
使用 Flask-Migrate 管理数据库模式变化的步骤如下。
(1) 对模型类做必要的修改。
(2) 执行 flask db migrate 命令,自动创建一个迁移脚本。
(3) 检查自动生成的脚本,根据对模型的实际改动进行调整。
(4) 把迁移脚本纳入版本控制。
(5) 执行 flask db upgrade 命令,把迁移应用到数据库中。
flask db migrate 子命令用于自动创建迁移脚本:
(venv) $ flask db migrate -m "initial migration"
INFO [alembic.migration] Context impl SQLiteImpl.
INFO [alembic.migration] Will assume non-transactional DDL.
INFO [alembic.autogenerate] Detected added table 'roles'
INFO [alembic.autogenerate] Detected added table 'users'
INFO [alembic.autogenerate.compare] Detected added index
'ix_users_username' on '['username']'
Generating /home/flask/flasky/migrations/versions/1bc
594146bb5_initial_migration.py...done5.7.3. 更新数据库
检查并修正好迁移脚本之后,执行 flask db upgrade 命令,把迁移应用到数据库中:
(venv) $ flask db upgrade
INFO [alembic.migration] Context impl SQLiteImpl.
INFO [alembic.migration] Will assume non-transactional DDL.
INFO [alembic.migration] Running upgrade None -> 1bc594146bb5, initial migration对第一个迁移来说,其作用与调用 db.create_all() 方法一样。但在后续的迁移中,flask db upgrade 命令能把改动应用到数据库中,且不影响其中保存的数据。
如果你按照之前的说明操作过,那么已经使用
db.create_all()函数创建了数据库文件。此时,flask db upgrade命令将失败,因为它试图创建已经存在的数据库表。一种简单的处理方法是,把 data.sqlite 数据库文件删掉,然后执行flask db upgrade命令,通过迁移框架重新创建数据库。
06-flask博客项目实战一之项目框架搭建
1、创建一个目录,名为:microblog; 2、创建虚拟环境
C:\Users\Administrator>d:
D:\>cd D:\microblog
D:\microblog>python -m venv venv
D:\microblog>3、激活虚拟环境:activate
D:\microblog>cd D:\microblog\venv\Scripts
D:\microblog\venv\Scripts>activate
(venv) D:\microblog\venv\Scripts>注:退出虚拟环境 deactivate
4、安装Flask:pip install flask 安装指定版本的第三方库可用命令:pip install flask==版本号
(venv) D:\microblog\venv\Scripts>pip install flask
Collecting flask
Using cached https://files.pythonhosted.org/packages/7f/e7/08578774ed4536d3242b14dacb4696386634607af824ea997202cd0edb4b/Flask-1.0.2-py2.py3-none-any.whl
Collecting Werkzeug>=0.14 (from flask)
Using cached https://files.pythonhosted.org/packages/20/c4/12e3e56473e52375aa29c4764e70d1b8f3efa6682bef8d0aae04fe335243/Werkzeug-0.14.1-py2.py3-none-any.whl
Collecting itsdangerous>=0.24 (from flask)
Using cached https://files.pythonhosted.org/packages/dc/b4/a60bcdba945c00f6d608d8975131ab3f25b22f2bcfe1dab221165194b2d4/itsdangerous-0.24.tar.gz
Collecting Jinja2>=2.10 (from flask)
Using cached https://files.pythonhosted.org/packages/7f/ff/ae64bacdfc95f27a016a7bed8e8686763ba4d277a78ca76f32659220a731/Jinja2-2.10-py2.py3-none-any.whl
Collecting click>=5.1 (from flask)
Using cached https://files.pythonhosted.org/packages/34/c1/8806f99713ddb993c5366c362b2f908f18269f8d792aff1abfd700775a77/click-6.7-py2.py3-none-any.whl
Collecting MarkupSafe>=0.23 (from Jinja2>=2.10->flask)
Using cached https://files.pythonhosted.org/packages/4d/de/32d741db316d8fdb7680822dd37001ef7a448255de9699ab4bfcbdf4172b/MarkupSafe-1.0.tar.gz
Installing collected packages: Werkzeug, itsdangerous, MarkupSafe, Jinja2, click, flask
Running setup.py install for itsdangerous ... done
Running setup.py install for MarkupSafe ... done
Successfully installed Jinja2-2.10 MarkupSafe-1.0 Werkzeug-0.14.1 click-6.7 flask-1.0.2 itsdangerous-0.24可看到会附带安装好:Werkzeug, itsdangerous, MarkupSafe, Jinja2, click。 并可在目录D:\microblogvenv\Lib\site-packages下查看到。 上述重要库对应版本:
| 库名 | 版本号 | 简要说明 |
|---|---|---|
| flask | 1.0.2 | 内核 |
| werkzeug | 0.14.1 | 核心1,路由模块 |
| jinja2 | 2.10 | 核心2,模板引擎 |
| itsdangerous | 0.24 | (加密数据)签名模块 |
| MarkupSafe | 0.23 | 为Python实现XML / HTML / XHTML 标记安全字符串 |
| click | 5.1 | 命令行工具库 |
以上的库均由Armin Ronacher及其Flask团队pallets开发编写。
5、创建一个“Hello,World!” Flask应用程序
0)、该应用程序将存在于一个包(app)中。在Python中,包含init.py文件的子目录被视为包,其可被导入。当导入一个包时,init.py将会执行并定义“暴露”给外部的标识(告诉你们,我是一个包 package)。
在D:\microblog下创建一个目录,名为app。并写一个init.py文件,表明app是一个包 package。
init.py,它将创建Flask应用程序实例,代码如下:
from flask import Flask#从flask包中导入Flask类
app = Flask(__name__)#将Flask类的实例 赋值给名为 app 的变量。这个实例成为app包的成员。
#print('等会谁(哪个包或模块)在使用我:',__name__)
from app import routes#从app包中导入模块routes
#注:上面两个app是完全不同的东西。两者都是纯粹约定俗成的命名,可重命名其他内容。上述脚本只是创建了一个作为Flask类的实例的应用程序对象,Flask类是从flask包中导入的。传递给Flask类的变量name是一个Python预定义的变量,该变量设置为使用它的模块的名字。可加入一句打印用于理解,如上(不用时注释掉或删除该行代码)。当应用程序运行时,可看到打印的是包 app。 当需要加载如模板文件等相关资源时,Flask将使用此处传递的模块的位置作为起点。 传递的变量name总是以正确的方式配置给Flask。 接着,从包 app中导入模块routes,目前尚未编写它。
还注意到:routes模块是在脚本底部导入,而不是顶部,因为它始终是完成的。底部导入是避免循环导入(circular import)问题的解决方法。在接下来的routes模块中,需要导入这个脚本(init.py)中的变量app,因此将其放置在底部导入,以避免由这俩个文件之间的相互引用引起的error。
1)、routes模块
路由,是处理URL 和函数 之间关系的程序。使用route()装饰器来把函数绑定到URL。 在Flask中,应用程序 路由的处理程序被编写为Python函数,称为 视图函数,例此模块中的index()。 视图函数映射到一个或多个路由URL,以便Flask知道客户端请求给定URL时要执行的逻辑(Python代码)。

app/routes.py代码:
from app import app#从app包中导入 app这个实例
#2个路由
@app.route('/')
@app.route('/index')
#1个视图函数
def index():
return "Hello,World!"#返回一个字符串@app.route装饰器 为作为一个参数给定的URL和函数之间创建关联。代码中有两个装饰器,它们共同将URL / 和 /index 关联至index()函数。这意味着当浏览器这俩个URL中任一个时,Flask将调用此函数(index())并将其返回值(字符串)作为响应 Response传递回浏览器。
2)、为完成这个简单的应用程序,还需在顶层 top-level定义一个Flask应用程序实例 的Python脚本,命名为microblog.py,并仅有一行代码,即导入应用程序实例。代码如下:
from app import app#从app包中导入变量app(它是作为app包成员的变量)目前为止,项目结构图:
microblog/
venv/
app/
__init__.py
routes.py
microblog.py3)运行程序。 运行之前,设置FLASK_APP环境变量,它会告诉Flask如何导入刚写的应用程序。
(venv) D:\microblog\venv\Scripts>cd D:\microblog
(venv) D:\microblog>set FLASK_APP=microblog.py使用命令 flask run运行程序:
(venv) D:\microblog>flask run
* Serving Flask app "microblog.py"
* Environment: production
WARNING: Do not use the development server in a production environment.
Use a production WSGI server instead.
* Debug mode: off
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
127.0.0.1 - - [02/Aug/2018 16:36:28] "GET / HTTP/1.1" 200 -
127.0.0.1 - - [02/Aug/2018 16:36:29] "GET /favicon.ico HTTP/1.1" 404 -
127.0.0.1 - - [02/Aug/2018 16:36:41] "GET /index HTTP/1.1" 200 -服务器初始化后,它将等待客户端链接。flask run命令指示服务器在IP地址127.0.0.1上运行,也即 localhost。 网络服务器侦听特定端口号上的连接。部署在生产Web服务器上的应用程序通常侦听端口443(若未实施加密,可能是侦听80),但访问这些端口需要管理权限。上述应用程序是开发环境中运行,Flask将使用免费提供的端口5000。浏览器地址栏输入如下URL并回车:
http://localhost:5000/或使用其他URL:
http://localhost:5000/index注:环境变量不会在终端中被记住,比如打开新的终端窗口时,得重新设置它。不过,Flask允许注册 在运行flask 命令时要自动导入的环境变量。要使用这个选项,得安装python-dotenv包:
(venv) D:\microblog>pip install python-dotenv然后,在项目的顶级目录中创建一个.env文件(如microblog/microblog.env),文件中编写环境变量名称、值:
FLASK_APP=microblog.py参考 https://blog.miguelgrinberg.com/post/the-flask-mega-tutorial-part-i-hello-world
07-flask博客项目实战二之模板使用
1. 模板定义
如有一个预期:html主页有一个 欢迎用户的标题。目前这个应用程序还没用户的概念,也没用户系统。但可用一个 模拟用户,用Python字典实现:
user = {'username':'Miguel'}创建模拟对象 是一种有用的技术,使我们可专注于应用程序已有的部分,而不必担心尚不存在的部分。 app/routes.py:从视图函数中返回完整的HTML页面
from app import app
@app.route('/')
@app.route('/index')
def index():
user = {'username':'Miguel'}
return '''
<html>
<head>
<title>Home Page - Microblog</title>
<head>
<body>
<h1>Hello,''' + user['username']+ '''!</h1>
<body>
</html>
'''在cmd中运行程序。更新视图功能,并查看应用程序在浏览器中的显示效果。
C:\Users\Administrator>d:
D:\microblog>cd D:\microblog\venv\Scripts
D:\microblog\venv\Scripts>activate
(venv) D:\microblog\venv\Scripts>cd D:\microblog
(venv) D:\microblog>set FLASK_APP=microblog.py
(venv) D:\microblog>flask run
* Serving Flask app "microblog.py"
* Environment: production
WARNING: Do not use the development server in a production environment.
Use a production WSGI server instead.
* Debug mode: off
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
127.0.0.1 - - [02/Aug/2018 18:11:46] "GET / HTTP/1.1" 200 -很明显,HTML代码 和.py代码混在一起了,很不利于今后的维护、理解。就得将网络布局(呈现)与应用程序的逻辑处理代码 分开/分离。模板在此闪亮登场!将助实现表示、业务逻辑的分离。
在Flask中,模板是作为单独的文件编写的,存放在应用程序 包内的 ***templates***文件夹(约定俗成命名为 templates)下。
即在app目录下创建templates文件夹:
(venv) D:\microblog>cd D:\microblog\app
(venv) D:\microblog\app>mkdir templates在此目录下创建一个HTML文件index.html,它将和上方index()这个视图函数一样的视图功能。 app/templates/index.html:主页面模板
<html>
<head>
<title>{{ title }} - Microblog</title>
</head>
<body>
<h1>Hello,{{ user.username }}!</h1>
</body>
</html>这是一个标准的、简单的HTML页面。但有一点跟我们写HTML代码不同是title标签、 h1标签中的两对花括号,在此它是个 占位符,作用是将表达式(如文字、数学式子、比较运算符等,其实在Python中是一个Python语句) 打印到模板进行输出。具体参考Jinja2官网文档。 这些占位符表示HTML页面中可变的部分,并且只在运行时才知道。
现在HTML页面的呈现已在HTML模板中了,这样接着就可简化一下视图函数index()了。修改routes.py文件 app/routes.py:使用render_template()函数
from app import app
from flask import render_template#从flask包中导入render_template函数
@app.route('/')
@app.route('/index')
def index():
user = {'username':'Miguel'}
return render_template('index.html', title='Home', user=user)将模板(index.html)转换为完整HTML页面的操作称之为 呈现(render,译作 递交、表达、给予,在此译作 “渲染”)。为了渲染模板,由从flask包中导入的render_template()完成,此函数“携带”模板文件名(index.html)、模板参数的变量列表,并返回相同的模板,不过其中所有占位符都替换为实际值。
render_template()函数调用与Flask框架捆绑在一起的Jinja2模板引擎。Jinja2会用相应的值替换块,这个相应的值由render_template()调用时提供的参数给出。 参考:flask.render_template()
2. 控制结构----if条件、for循环、继承
上述过程只是理解了:Jinja2模板引擎 如何在渲染过程中用实际值 替换 (模板中的)占位符。 接下来将认识到更多 Jinja2在模板文件中支持的更多强大操作:if条件、for循环、继承等。 源自官网的这句话:
There are a few kinds of delimiters. The default Jinja delimiters are configured as follows:
{% ... %} for Statements
{{语句 }} for Expressions to print to the template output
{# ... #} for Comments not included in the template output
# ... ## for Line Statementsif、for、继承均在{% ... %}块中写控制语句。
2.1 if条件
形如:
{% if title %}
...语句块
{% else %}
...语句块
{% endif %}app/templates/index.html:模板中添加条件语句
<html>
<head>
{% if title %}
<title>{{ title }} - Microblog</title>
{% else %}
<title>Welcome to Microblog!</title>
{% endif %}
</head>
<body>
<h1>Hello,{{ user.username }}!</h1>
</body>
</html>上述代码中if语句块的功能是:若视图函数index()没有传递title占位符变量的值,则index.html模板将会提供默认值(else语句块中),而不是显示空标题。 尝试将routes.py中render_template()中的title='Home',删除。效果:图略
2.2. for循环
在模板中形如:
{% for post in posts %}
...语句块
{% endfor %}需求:登录用户可在主页中查看最新的帖子。 实现: 首先,用虚拟对象的方法来创建一些用户、帖子,以供显示。 app/routes.py:视图函数中的假帖子
from app import app
from flask import render_template#从flask包中导入render_template函数
@app.route('/')
@app.route('/index')
def index():
user = {'username':'Miguel'}#用户
posts = [#创建一个列表:帖子。里面元素是两个字典,每个字典里元素还是字典,分别作者、帖子内容。
{
'author': {'username':'John'},
'body':'Beautiful day in Portland!'
},
{
'author': {'username':'Susan'},
'body':'The Avengers movie was so cool!'
}
]
return render_template('index.html', title='Home', user=user, posts=posts)帖子列表 可包含任意数量的元素,由视图函数index()决定将在页面中显示的帖子数量。而模板index.html不能假设这有多少个帖子,因此它需要准备好以通用方式呈现视图发送来的尽可能多的帖子。在模板index.html中,用for循环遍历所有的帖子并呈现。 app/templates/index.html:在模板中的for循环
<html>
<head>
{% if title %}
<title>{{ title }} - Microblog</title>
{% else %}
<title>Welcome to Microblog!</title>
{% endif %}
</head>
<body>
<h1>Hello,{{ user.username }}!</h1>
{% for post in posts %}
<div><p>{{ post.author.username }} says: <b>{{ post.body }}</b></p></div>
{% endfor %}
</body>
</html>运行程序,图略
2.3. 模板继承
形如:
{% extends "base.html" %}
{% block content %}
...
{% endblock %}现在,大部分Web应用程序在页面顶部有一个导航栏,它常包含一些常用链接:如登录、退出、编辑个人资料等。可以很轻松地将导航栏添加到index.html模板,甚至更多的HTML页面中。但随着应用程序的增长(页面数量的增多),这些页面都将使用相同的导航栏,不可能每一个页面都增加一份相同的导航栏代码。
Jinja2具有模板继承功能,完美解决上述问题。在实际操作中,将所有模板共有的页面布局部分移至基础模板中,其他模板则继承自它。
实例:实现一个简单的导航栏,其他模板继承它。 在app/templates目录下创建一个基础模板文件 base.html。 app/templates/base.html:带导航栏的基础模板
<html>
<head>
{% if title %}
<title>{{ title }} - Microblog</title>
{% else %}
<title>Welcome to Microblog</title>
{% endif %}
</head>
<body>
<div>Microblog:<a href="/index">Home</a></div>
<hr>
{% block content %}
{% endblock %}
</body>
</html>在上述基础模板中,块block 控制语句用于定义派生模板可自行插入的位置。块block 被赋予唯一的名字 content,派生模板在提供其内容时可引用这个名称。
修改index.html这个模板,让其继承base.html模板。 app/templates/index.html:从基础模板继承
{% extends "base.html" %}
{% block content %}
<h1>Hello,{{ user.username }}!</h1>
{% for post in posts %}
<div><p>{{ post.author.username }} says: <b>{{ post.body }}</b></p></div>
{% endfor %}
{% endblock %}base.html基础模板 实现处理常规页面的结构,则派生模板index.html简化大部分内容。 extends语句 建立了两个模板之间的继承关系,因此,Jinja2就会知道:当它被要求渲染index.html时,需要将其嵌入base.html中。这俩模板具有匹配的block语句 名称content,这就是Jinja2如何将两个模板合并为一个模板的方法。 
运行程序,图略
今后,当再需要为应用程序创建其他页面时,就可省去编写相同代码的麻烦,并让应用程序的所有页面共享相同的外观,而只需一个步骤:创建继承自base.html模板的派生模板。
目前为止,项目结构:
microblog/
venv/
app/
templates/
base.html
index.html
__init__.py
routes.py
microblog.py参考 https://blog.miguelgrinberg.com/post/the-flask-mega-tutorial-part-ii-templates
08-flask博客项目实战三之表单
实现:如何通过Web表单接受用户的输入。
其中,Web表单是任何Web应用程序中基本的构建块之一。在此,将使用表单来允许用户提交博客帖子,以及登录应用程序。
1. Flask-WTF简介和安装
在Flask中,处理应用程序中的Web表单,将使用到**Flask-WTF**扩展库,它是Flask和WTForms的简单集成,主要功能有:使用CSRF(Cross-site request forgery,译作 跨站请求伪造)令牌保护表单、文件上传、支持reCAPTCHA(译作 反全自动区分计算机和人类的图灵测试,简单点就是:验证码)。扩展是Flask生态系统中非常重要的一部分。今后还会需要更多的扩展。
进入虚拟环境中,安装Flask-WTF:pip install flask-wtf
(venv) D:\microblog>pip install flask-wtf
Collecting flask-wtf
Using cached https://files.pythonhosted.org/packages/60/3a/58c629472d10539ae5167dc7c1fecfa95dd7d0b7864623931e3776438a24/Flask_WTF-0.14.2-py2.py3-none-any.whl
Requirement already satisfied: Flask in d:\microblog\venv\lib\site-packages (from flask-wtf)
Collecting WTForms (from flask-wtf)
Using cached https://files.pythonhosted.org/packages/9f/c8/dac5dce9908df1d9d48ec0e26e2a250839fa36ea2c602cc4f85ccfeb5c65/WTForms-2.2.1-py2.py3-none-any.whl
Requirement already satisfied: Jinja2>=2.10 in d:\microblog\venv\lib\site-packages (from Flask->flask-wtf)
Requirement already satisfied: click>=5.1 in d:\microblog\venv\lib\site-packages (from Flask->flask-wtf)
Requirement already satisfied: Werkzeug>=0.14 in d:\microblog\venv\lib\site-packages (from Flask->flask-wtf)
Requirement already satisfied: itsdangerous>=0.24 in d:\microblog\venv\lib\site-packages (from Flask->flask-wtf)
Requirement already satisfied: MarkupSafe>=0.23 in d:\microblog\venv\lib\site-packages (from Jinja2>=2.10->Flask->flask-wtf)
Installing collected packages: WTForms, flask-wtf
Successfully installed WTForms-2.2.1 flask-wtf-0.14.2将附带安装WTForms,因为它是Flask-WTF的一部分。在D:\microblogvenv\Lib\site-packages下将看到新安装的这俩个扩展。
| 扩展名 | 版本号 | 简要说明 |
|---|---|---|
| flask-wtf | 0.14.2 | 2017-08-13发布,主要功能:使用CSRF令牌保护表单、文件上传、支持reCAPTCHA |
| wtforms | 2.2.1 | 创建表单 |
2. 配置 configuration
目前为止,这个应用程序足够简单,无需担心它的配置。Flask(以及Flask扩展)在如何执行操作方面提供了很多自由,并需要做一些决定,并将这些决定作为一个配置变量列表传递给框架。
应用程序 有多种格式可指定配置选项。最基本的方案:在app.config这个字典中,将定义的变量作为键。形如:
app = Flask(__name__)
app.config['SECRET_KEY'] = 'I am a secret, you can't guess.'
#需要的话,可继续添加更多的变量尽管上述语法可为Flask成功创建配置选项,但根据 关注点分离原则(Separation of concerns, SoC),所以不要将配置放在创建应用程序的相同位置,而是:将配置保存在单独的*.py*文件中,并使用类存储配置变量,将该.py文件放在项目顶级目录下。 D:\microblog\config.py:密钥配置
import os
class Config:
SECRET_KEY = os.environ.get('SECRET_KEY') or 'you will never guess'SECRET_KEY这个配置变量,将会被Flask及其扩展使用其值作为加密秘钥,用于生产签名或令牌。而Flask-WTF使用它来保护Web表单来免受CSFR攻击。
密钥的值 是具有两个术语的表达式,由or运算符连接。第一个术语是查找环境变量的值;第二个术语是一个硬编码的字符串。当然这个安全性还是很低的。当将应用程序部署在生产服务器上时,得设置一个安全级别高的。
其中os.environ是获取本机系统的各种信息(如环境变量等,你打印出来就明白了,哈哈),它是一个字典。我觉得os.environ.get('SECRET_KEY')在开发环境中并没有用,是None,不知部署后是什么。 有了上述这个配置文件,接下来得让Flask应用程序读取并应用它。在创建Flask应用程序实例后,就用app.config.from_object()方法完成:
app/init.py:Flask配置
from flask import Flask
from config import Config#从config模块导入Config类
app = Flask(__name__)
app.config.from_object(Config)
from app import routes查看刚才配置的密钥是什么:
(venv) D:\microblog>python
Python 3.6.3 (v3.6.3:2c5fed8, Oct 3 2017, 18:11:49) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> from microblog import app
>>> app.config['SECRET_KEY']
'you will never guess'
>>>3. 用户登录表单
Flask-WTF扩展使用Python类来表示Web表单。表单类只是将表单的字段定义为类变量。
再次根据SoC(关注点分离原则),新建一个forms.py模块来存放Web表单类。在此,定义一个用户登录表单,要求用户输入用户名、密码,还包含“Remember Me”复选框、提交按钮。 app/forms.py:用户登录表单
from flask_wtf import FlaskForm#从flask_wtf包中导入FlaskForm类
from wtforms import StringField,PasswordField,BooleanField,SubmitField#导入这些类
from wtforms.validators import DataRequired
class LoginForm(FlaskForm):
username = StringField('Username', validators=[DataRequired()])
password = PasswordField('Password', validators=[DataRequired()])
remember_me = BooleanField('Remember Me')
submit = SubmitField('Sign In')在Flask生态下,Flask扩展一般都使用flask_<name>这样的命名约定作为在模块中顶级导入的符号。在这个情况下,Flask-WTF的所有符号都在flask_wtf下,这也是FlaskForm基类在app/forms.py顶部导入的地方。
from wtforms import StringField,PasswordField,BooleanField,SubmitField这条语句表示:这个用户登录表单的字段类型的4个类是直接从WTForms包导入的,因为Flask-WTF扩展是不提供自定义(字段类型?)版本。对于每个字段,将在LoginForm类中将对象创建为类变量。每个字段都有一个描述或标签作为第一个参数。
在某些字段中看到的可选参数validators将验证行为附加到字段中,如用户名、密码肯定是需要进行验证的。DataRequired验证器 只是简单地检查该字段不会提交为空。当然还有其他的验证器可用。
4. 用户登录-表单模板
有了上一步的登录表单,接下来得将表单添加到HTML模板中,让其在网页上呈现。 LoginForm类中定义的字段知道如何将自己渲染为HTML。 app/templates/login.html:用户登录表单模板
{% extends "base.html" %}
{% block content %}
<h1>Sign In</h1>
<form action="" method="post" novalidate>
{{ form.hidden_tag() }}
<p>
{{ form.username.label }}<br>
{{ form.username(size=32) }}
</p>
<p>
{{ form.password.label }}<br>
{{ form.password(size=32) }}
</p>
<p>{{ form.remember_me() }} {{ form.remember_me.label }}</p>
<p>{{ form.submit() }}</p>
</form>
{% endblock %}这个用户登录表单模板使用了extends继承语句继承base.html模板,以确保一致的布局,即基础模板包含了所有页面的顶部导航栏。
在此的用户登录表单模板期望从LoginForm类实例化的表单对象作为参数给出,这个参数将由登录视图函数(目前还未编写)发送。
以下将讲述HTML知识,上述这段HTML代码中:<form>标签用作Web表单的容器。 其中
action属性表示用于告知浏览器当用户在表单中输入信息提交时应使用的URL。该属性设置为空字符串时,表单将提交到当前位于地址栏的URL,即在页面上呈现表单的URL。method属性用于指定在将表单提交到服务器时应使用的HTTP请求方法。默认情况下,是通过GET请求发送它。但几乎在所有情况下,使用POST请求会获得更好的用户体验,因为此类请求可在请求正文中提交表单数据,GET请求将表单字段添加到URL,会让浏览器地址栏变得混乱。novalidate属性用于告知浏览器不对此表单中的字段运用验证,这有效地将此任务留给服务器中运行的Flask应用程序。当然,使用novalidate完全是可选的,但对于第一种形式,设置它是很重要的,因为这将允许在本章后面的测试服务器端验证。- form.hidden_tag()这个模板参数 生成一个隐藏字段,其中包括用来防止CSRF攻击的令牌。要使表单受保护,需要做的是包含此隐藏字段,并在Flask配置中定义的SECRET_KEY变量。
写过HTML Web表单的同学可能会发现这个模板中没有HTML字段,这是因为表单对象中的字段知道如何将自己呈现(渲染)为HTML,
需要做的就是{ { form.<field_name>.label } }需要的字段标签、{ { form.<field_name>() } }需要的字段。
对于需要其他HTML属性的字段,可将这些属性作为参数传递。此模板中的用户名、密码字段将size作为参数添加到<input>这个HTML标签作为属性。这还是可将CSS类、或ID附加到表单字段的方法。
5. 用户登录-表单视图
在编写完上一步的用户登录表单模板后,想要在浏览器中看到此表单的最后一步是:在应用程序中编写一个它的视图函数,用于渲染该模板。
因此,编写一个映射到/login URL的视图函数login(),并将其传递给模板进行渲染。在routes模块中增加代码:
app/routes.py:用户登录视图函数
from flask import render_template
from app import app
from app.forms import LoginForm
#...
@app.route('/login')
def login():
form = LoginForm()#表单实例化对象
return render_template('login.html', title='Sign In', form=form)上述视图函数很简单,从forms.py模块中导入LoginForm类,然后实例化该类,最后将其发送到模板。form=form,return中将form实例对象赋值给form变量,这将获得表单字段所需的全部内容。
为了便于访问登录表单,在基础模板中改进,即在导航栏中包含指向它的链接: app/templates/base.html:导航栏中增加登录链接
<div>
Microblog:
<a href="/index">Home</a>
<a href="/login">Login</a>
</div>此刻,运行应用程序就可浏览器中查看该表单了。效果:图略
6. 接收表单数据
尝试点击上述“Sign In”提交按钮,浏览器将出现405错误“Method Not Allowed”。图略
在上一步中,用户登录的视图函数执行了一半的工作,即可在网页上显示表单。但它没有处理用户提交的数据的逻辑。这是Flask-WTF让这项逻辑处理变得非常简单的优势。更新用户登录视图函数代码,它接受、验证用户提交的数据: app/routes.py:接收登录凭据
from flask import render_template,flash,redirect
@app.route('/login',methods=['GET','POST'])
def login():
form = LoginForm()
if form.validate_on_submit():
flash('Login requested for user {},remember_me={}'.format(form.username.data,form.remember_me.data))
return redirect('/index')
return render_template('login.html',title='Sign In',form=form)在@app.routes()装饰器中参数methods作用是:告诉Flask这个视图函数接受GET和POST请求方法,覆盖默认值(即只接受GET请求)。HTTP协议中,GET请求是将信息返回给客户端(如浏览器)的请求,到目前为止,该应用程序中的所有请求都属于这种类型;POST 请求通常在浏览器上服务器提交表单数据时使用。上述出现“Method Not Allowed”,是因为浏览器尝试发送POST请求,而应用程序没有配置去接受它。
form.validate_on_submit()方法完成所有表单处理工作。当浏览器发送GET接收带有表单的网页请求时,此方法将返回False,此时函数会跳过if语句并直接在函数的最后一行呈现模板。 当用户在浏览器按下提交按钮时,浏览器发送POST请求,form.validate_on_submit()将收集所有数据,运行附加到字段的所有验证器,如果一切正常,它将返回True,表明数据有效且可由应用程序处理。但如果至少有一个字段未通过验证,则函数就会返回False,接着就像上述GET请求那样。 当form.validate_on_submit()返回True,这个登录视图函数将调用两个函数,分别是flash()、redirect(),均从flask包导入的。 flash() 用于向用户显示消息,如让用户知道某些操作是否成功。目前为止,将使用其机制作为临时解决方案,因为暂无用户登录未真实所需的基础结构,此时只是显示一条消息用于确认应用程序已收到凭据。 redirect()用于指示客户端(浏览器)自动导航到作为参数给出的其他页面(如上述代码中的/index页面,即重定向到应用程序的/index页面)。
当调用flash()函数时,Flask会存储该消息,但闪烁的消息不会神奇地出现在Web页面中。应用程序的模板需要以适用于站点布局的方式呈现/渲染这些闪烁的消息。因此,将这些消息添加到基础模板中,以便所有模板都继承此功能。更新基础模板: app/templates/base.html:基础模板中的闪烁消息
<html>
<head>
{% if title %}
<title>{{ title }} - Microblog</title>
{% else %}
<title>Welcome to Microblog</title>
{% endif %}
</head>
<body>
<div>Microblog:<a href="/index">Home</a><a href="/login">Login</a></div>
<hr>
{% with messages = get_flashed_messages() %}
{% if messages %}
<ul>
{% for message in messages %}
<li>{{ message }}</li>
{% endfor %}
</ul>
{% endif %}
{% endwith %}
{% block content %}
{% endblock %}
</body>
</html>上述代码中,使用with结构将调用get_flashed_messages()的结果分配给变量messages,都在模板的上下文。这个get_flashed_messages()函数来自Flask,并返回flash()之前已注册的所有消息的列表。接着if语句判断messages是否具有某些内容,在这种情况下,一个ul标签被渲染成每个消息作为一个li标签列表项。而这种渲染风格看起来不太好,但Web应用程序样式化的主题将在稍后出现。
这些闪烁的消息的一个有趣属性是:一旦通过get_flashed_messages()请求它们,它们就会从列表中删除,因此它们在flash()调用后只出现一次。
运行程序,再次测试表单是如何工作的。确保将用户名或密码字段为空来提交表单,以查看DataRequired验证器如何暂停提交过程。
C:\Users\Administrator>d:
D:\>cd D:\microblog\venv\Scripts
D:\microblog\venv\Scripts>activate
(venv) D:\microblog\venv\Scripts>cd D:\microblog
(venv) D:\microblog>flask run
* Serving Flask app "microblog.py"
* Environment: production
WARNING: Do not use the development server in a production environment.
Use a production WSGI server instead.
* Debug mode: off
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
127.0.0.1 - - [07/Aug/2018 16:16:26] "GET /login HTTP/1.1" 200 -用户名或密码为空时提交表单,网页没反应。都不为空时,随意输入。 图略
点击Sign in按钮后,倒是出现了一条消息:Login requested for user 123456@qq.com,remember_me=Flase 图略
7. 增强字段验证
附加到表单字段的验证器可防止无效数据接受到应用程序中。应用程序处理无效表单输入的方式是重新显示表单,让用户进行必要的更正。
当提交无效数据时,却没有明显提示用户提交的数据有问题,只是重新返回表单,这将影响用户体检。因此,现在的任务是:通过在验证失败的每个字段傍边增加有意义的错误提示来改善用户体验。
实际上,表单验证器已经生成了这些描述性错误消息,因此,缺少的是在模板中用于渲染/呈现它们的一些额外逻辑。在用户登录模板的用户名、密码字段中添加字段验证消息:更新代码 app/templates/login.html:提示字段验证错误消息
{% extends "base.html" %}
{% block content %}
<h1>Sign In</h1>
<form action="" method="post" novalidate>
{{ form.hidden_tag() }}
<p>
{{ form.username.label }}<br>
{{ form.username(size=32) }}<br>
{% for error in form.username.errors %}
<span style="color:red;">[{{ error }}]</span>
{% endfor %}
</p>
<p>
{{ form.password.label }}<br>
{{ form.password(size=32) }}<br>
{% for error in form.password.errors %}
<span style="color:red;">[{{ error }}]</span>
{% endfor %}
</p>
<p>{{ form.remember_me() }} {{ form.remember_me.label }}</p>
<p>{{ form.submit() }}</p>
</form>
{% endblock %}上述代码中,只是在用户名、密码字段之后添加for循环,以红色字体消息渲染错误消息。一般规则下,任何附加验证器的字段都会通过form.<field_name>.errors添加错误消息。这将是一个列表,因为字段可以附加多个验证器,并且多个可能提供错误消息提示给用户。
如果尝试提交空用户名或密码的表单,将看到红色错误提示,效果:图略
8. 生成URL
用户登录表单现在比较完整了,下面将学习在模板包含链接和重定向的方法。 例:基础模板中的当前导航栏
<div>
Microblog:
<a href="/index">Home</a>
<a href="/login">Login</a>
</div>登录视图函数还定义了传递给redirect()函数的链接:
@app.route('/login', methods=['GET', 'POST'])
def login():
form = LoginForm()
if form.validate_on_submit():
# ...
return redirect('/index')
# ...直接在模板、源文件中编写链接的一个问题是:如果将来某天要重新组织链接,将不得不修改整个应用程序的这个链接,搜索、替换。
为更好地控制这些链接,Flask提供了一个名为 url_for()函数,它使用URL的内部映射到视图函数来生成URL。例:url_for('login')返回/login;url_for('index')返回/index。url_for()中的参数就是端点名称,也就是视图函数的名字。
使用函数名称而不是URL的优点:URL比视图函数名称更可能发生变化;某些URL很可能包含动态组件,手动生成这URL需要连接多个元素,这极易出错,而url_for()能生成这些复杂的URL。
因此,今后每次应用程序要生成URL时,都使用url_for()。 更新基础模板中的代码: app/templates/base.html:使用url_for()进行链接
...
<div>
Microblog:
<a href="{{ url_for('index') }}">Home</a>
<a href="{{ url_for('login') }}">Login</a>
</div>
...更新login()视图函数中的代码: app/routes.py:对链接使用url_for()函数
from flask import render_template, flash, redirect, url_for
# ...
@app.route('/login', methods=['GET', 'POST'])
def login():
form = LoginForm()
if form.validate_on_submit():
# ...
return redirect(url_for('index'))
# ...目前为止,项目结构:
microblog/
venv/
app/
templates/
base.html
index.html
login.html
__init__.py
forms.py
routes.py
microblog.py参考 https://blog.miguelgrinberg.com/post/the-flask-mega-tutorial-part-iii-web-forms
09-flask博客项目实战四之数据库
数据库能为应用程序提供有效检索的持久数据。这是本章学习的内容。
1. Flask中的数据库
Flask本身并不支持数据库。意味着可以自由选择适合应用程序的数据库。
在Python中对于数据库,有很多选择,并且很多带有Flask扩展,可很好地与Flask Web应用程序集成。数据库分为两大类:关系型、非关系型。后者称为NoSQL,即它们没有实现流行的关系查询语言SQL。关系型数据库适合具有结构化数据的应用程序,如用户列表、博客帖子等;而NoSQL数据库适合具有结构不太明确的。
本章将再使用两个Flask扩展:Flask-SQLAlchemy、Flask-Migrate。
其中,Flask-SQLAlchemy为流行的**SQLAlchemy包提供了一个Flask-friendly包装器,它是一个ORM。ORM允许应用程序使用高级实体**(如类、对象、方法)而不是表和SQL来管理数据库,它的工作是将高级操作转换为数据库命令。
关于SQLAlchemy的好处是:它不是一个ORM,而是许多关系数据库。SQLAlchemy支持很多数据库引擎,包括流行的MySQL、PostgreSQL、SQLite。这非常强大,因为可以使用不需要服务器的简单SQLite数据库进行开发,然后在生产服务器上部署应用程序时,可以选择更强大的MySQL或PostgreSQL服务器,而无需改变应用程序。
PS:学到一个单词 alchemy 译为 炼金术、魔力,SQLAlchemy是个有魔力的东西。
在虚拟环境中安装Flask-SQLAlchemy:pip install flask-sqlalchemy,将会自动附带安装sqlalchemy包。
| 库名称 | 版本号 | 简要说明 |
|---|---|---|
| sqlalchemy | 1.2.10 | SQLAlchemy不是数据库,而是操作数据库的工具包、是对数据库进行操作的一种框架,简化了数据库管理的操作。也是一个强大的关系型数据库框架。 |
| flask-sqlalchemy | 2.3.2 | Flask-SQLAlchemy 也是一种数据库框架,是一个Flask扩展,它包装了SQLAlchemy,支持多种数据库后台。无须关心SQL处理细节,一个基本关系对应一个类,而一个实体对应类的实例对象,通过调用方法操作数据库。 |
(venv) D:\microblog>pip install flask-sqlalchemy
Collecting flask-sqlalchemy
Using cached https://files.pythonhosted.org/packages/a1/44/294fb7f6bf49cc7224417cd0637018db9fee0729b4fe166e43e2bbb1f1c8/Flask_SQLAlchemy-2.3.2-py2.py3-none-any.whl
Requirement already satisfied: Flask>=0.10 in d:\microblog\venv\lib\site-packages (from flask-sqlalchemy)
Collecting SQLAlchemy>=0.8.0 (from flask-sqlalchemy)
Downloading https://files.pythonhosted.org/packages/8a/c2/29491103fd971f3988e90ee3a77bb58bad2ae2acd6e8ea30a6d1432c33a3/SQLAlchemy-1.2.10.tar.gz (5.6MB)
100% |████████████████████████████████| 5.6MB 208kB/s
Requirement already satisfied: Werkzeug>=0.14 in d:\microblog\venv\lib\site-packages (from Flask>=0.10->flask-sqlalchemy)
Requirement already satisfied: click>=5.1 in d:\microblog\venv\lib\site-packages (from Flask>=0.10->flask-sqlalchemy)
Requirement already satisfied: Jinja2>=2.10 in d:\microblog\venv\lib\site-packages (from Flask>=0.10->flask-sqlalchemy)
Requirement already satisfied: itsdangerous>=0.24 in d:\microblog\venv\lib\site-packages (from Flask>=0.10->flask-sqlalchemy)
Requirement already satisfied: MarkupSafe>=0.23 in d:\microblog\venv\lib\site-packages (from Jinja2>=2.10->Flask>=0.10->flask-sqlalchemy)
Installing collected packages: SQLAlchemy, flask-sqlalchemy
Running setup.py install for SQLAlchemy ... done
Successfully installed SQLAlchemy-1.2.10 flask-sqlalchemy-2.3.22. 数据库迁移
大多数数据库教程都涵盖数据库的创建、使用,但没有充分解决在应用程序在需要更改或增长时对现有数据库进行更新的问题。这是一个难点,因为关系数据库是以结构化数据为中心,在结构发生更改时,数据库中已有的数据需要迁移到修改后的结构中。
Flask-Migrate扩展是Alembic(PS:Alembic是SQLAlchemy作者编写的数据库迁移工具)的Flask包装器,是SQLAlchemy的数据库迁移框架。虽然使用数据库迁移为启动数据库添加了一些工作,但这是一个很小的代价,将为未来对数据库进行更改提供强大方法。 在虚拟环境中安装Flask-Migrate:pip install flask-migrate,将会自动附带安装Mako、alembic、python-dateutil、python-editor、six。
| 库名称 | 版本号 | 简要说明 |
|---|---|---|
| Flask-Migrate | 2.2.1 | Flask的数据库迁移扩展 |
| alembic | 1.0.0 | SQLAlchemy作者编写的数据库迁移工具 |
| Mako | 1.0.7 | 是一种嵌入式Python(即Python服务器页面)语言,提供一种熟悉的非XML语法 |
| python-dateutil | 2.7.3 | 对datetime模块的强大扩展 |
| python-editor | 1.0.3 | 以编程方式打开编辑器,捕获结果 |
| six | 1.11.0 | Python 2.x和3.x兼容库,目的是编写兼容两个Python版本的Python代码 |
C:\Users\Administrator>d:
D:\>cd D:\microblog\venv\Scripts
D:\microblog\venv\Scripts>activate
(venv) D:\microblog\venv\Scripts>cd D:\microblog
(venv) D:\microblog>pip install flask-migrate
Collecting flask-migrate
Using cached https://files.pythonhosted.org/packages/59/97/f681c9e43d2e2ace4881fa588d847cc25f47cc98f7400e237805d20d6f79/Flask_Migrate-2.2.1-py2.py3-none-any.whl
Requirement already satisfied: Flask-SQLAlchemy>=1.0 in d:\microblog\venv\lib\site-packages (from flask-migrate)
Collecting alembic>=0.7 (from flask-migrate)
Downloading https://files.pythonhosted.org/packages/96/c7/a4129db460c3e0ea8fea0c9eb5de6680d38ea6b6dcffcb88898ae42e170a/alembic-1.0.0-py2.py3-none-any.whl (158kB)
100% |████████████████████████████████| 163kB 246kB/s
Requirement already satisfied: Flask>=0.9 in d:\microblog\venv\lib\site-packages (from flask-migrate)
Requirement already satisfied: SQLAlchemy>=0.8.0 in d:\microblog\venv\lib\site-packages (from Flask-SQLAlchemy>=1.0->flask-migrate)
Collecting python-dateutil (from alembic>=0.7->flask-migrate)
Using cached https://files.pythonhosted.org/packages/cf/f5/af2b09c957ace60dcfac112b669c45c8c97e32f94aa8b56da4c6d1682825/python_dateutil-2.7.3-py2.py3-none-any.whl
Collecting Mako (from alembic>=0.7->flask-migrate)
Using cached https://files.pythonhosted.org/packages/eb/f3/67579bb486517c0d49547f9697e36582cd19dafb5df9e687ed8e22de57fa/Mako-1.0.7.tar.gz
Collecting python-editor>=0.3 (from alembic>=0.7->flask-migrate)
Using cached https://files.pythonhosted.org/packages/65/1e/adf6e000ea5dc909aa420352d6ba37f16434c8a3c2fa030445411a1ed545/python-editor-1.0.3.tar.gz
Requirement already satisfied: itsdangerous>=0.24 in d:\microblog\venv\lib\site-packages (from Flask>=0.9->flask-migrate)
Requirement already satisfied: click>=5.1 in d:\microblog\venv\lib\site-packages (from Flask>=0.9->flask-migrate)
Requirement already satisfied: Jinja2>=2.10 in d:\microblog\venv\lib\site-packages (from Flask>=0.9->flask-migrate)
Requirement already satisfied: Werkzeug>=0.14 in d:\microblog\venv\lib\site-packages (from Flask>=0.9->flask-migrate)
Collecting six>=1.5 (from python-dateutil->alembic>=0.7->flask-migrate)
Using cached https://files.pythonhosted.org/packages/67/4b/141a581104b1f6397bfa78ac9d43d8ad29a7ca43ea90a2d863fe3056e86a/six-1.11.0-py2.py3-none-any.whl
Requirement already satisfied: MarkupSafe>=0.9.2 in d:\microblog\venv\lib\site-packages (from Mako->alembic>=0.7->flask-migrate)
Installing collected packages: six, python-dateutil, Mako, python-editor, alembic, flask-migrate
Running setup.py install for Mako ... done
Running setup.py install for python-editor ... done
Successfully installed Mako-1.0.7 alembic-1.0.0 flask-migrate-2.2.1 python-dateutil-2.7.3 python-editor-1.0.3 six-1.11.03. Flask-SQLAlchemy配置
在开发过程中,这将使用SQLite数据库,它是开发小型应用程序的方便选择,有时甚至不是那么小,因为每个数据库都存储在磁盘上的单个文件中,并且不需要运行像MySQL、PostgreSQL的数据库服务器。
添加两个配置项到config.py中: microblog/config.py:Flask-SQLAlchemy配置
import os
basedir = os.path.abspath(os.path.dirname(__file__))#获取当前.py文件的绝对路径
class Config:
SECRET_KEY = os.environ.get('SECRET_KEY') or 'you will never guess'
SQLALCHEMY_DATABASE_URI = os.environ.get('DATABASE_URI') or 'sqlite:///' + os.path.join(basedir, 'app.db')
SQLALCHEMY_TRACK_MODIFICATIONS = FalseFlask-SQLAlchemy扩展从SQLALCHEMY_DATABASE_URI变量中获取应用程序数据库的位置。从环境变量中设置配置是一种很好的做法,并在环境中未定义变量时提供回退值。在这种情况下,将从DATABASE_URL环境变量中获取数据库URL;如果没有定义,将在应用程序主目录下配置一个名为app.db的数据库,该数据库存储在basedir变量中。
SQLALCHEMY_TRACK_MODIFICATIONS配置选项设置为False,意为禁用我不需要的Flask-SQLAlchemy的该特征,即追踪对象的修改并且发送信号。 更多的Flask-SQLAlchemy配置选项可参考 官网。
数据库将在应用程序中通过数据库实例表示。数据库迁移引擎也将有一个实例。这些是需要在应用程序之后需要创建的对象(即在app/init.py)。
app/*init*.py:初始化Flask-SQLAlchemy和Flask-Migrate,更新代码
from flask import Flask
from config import Config#从config模块导入Config类
from flask_sqlalchemy import SQLAlchemy#从包中导入类
from flask_migrate import Migrate
app = Flask(__name__)
app.config.from_object(Config)
db = SQLAlchemy(app)#数据库对象
migrate = Migrate(app, db)#迁移引擎对象
from app import routes,models#导入一个新模块models,它将定义数据库的结构,目前为止尚未编写4. 数据库模型
将存储在数据库中的数据由一组类来表示,通常称之为数据库模型。SQLAlchemy中的ORM层将做从这些类创建的对象映射到适当的数据库表的行所需的转换。
创建代表用户的模型,下图表示在users表中使用的数据。 
id字段通常在所有模型中,用作主键,将为数据库中的每个用户分配一个唯一的id值,该值存储在id字段中。大多情况下,主键由数据库自动分配,因此只需提供id字段并标记为主键。 username、email、password_hash字段都被定义为字符串(VARCHAR),并指定最大长度。其中,password_hash字段值得关注,我们要确保应用程序采用安全性最佳实践,因此不能将用户密码存储在数据库中。不直接写密码,而是密码哈希,大大提高安全性。
现在,已知道想要的用户表,将其转换为新模板models中的代码: app/models.py:用户数据库模型
from app import db
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(64), index=True, unique=True)
email = db.Column(db.String(120), index=True, unique=True)
password_hash = db.Column(db.String(128))
def __repr__(self):
return '<User {}>'.format(self.username)上述创建的User类继承自db.Model,它是Flask-SQLAlchemy所有模型的基类。这个类定义了几个字段作为类变量,这些字段是db.Column类创建的实例,它将字段类型作为参数、及其他可选参数,例 指定哪些字段是唯一的、索引的,这些对数据库搜索是非常重要的、有效的。
repr 方法用于告知Python如何打印此类的对象,这对调试很有用。在下面的Python解释会话中可看到repr()方法的实际应用:
>>> from app.models import User
>>> u = User(username='susan', email='susan@example.com')
>>> u
<User susan>5. 创建迁移存储库
上一节中创建的模型类定义了这个应用程序的初始数据库结构(或模式schema)。但随着应用程序的不断发展,将可能需要更改结构、添加新内容,还看修改或删除项目。Alembic(Flask-Migrate使用的迁移框架)将以不需要从头开始重新创建数据库的方式做到这些模式变化。
为了完成这个看似困难且麻烦的任务,Alembic维护了一个迁移存储库,它是一个存储其迁移脚本的目录。每次对数据库模式进行更改时,都会将迁移脚本添加到存储库,其中包含更改的详细信息。若要迁移运用于数据库,这些迁移脚本将按创建顺序执行。
Flask-Migrate通过flask命令公开其命令。运行程序时的flask run是Flask原生子命令。flask db 子命令由Flask-Migrate添加到管理有关数据库迁移的一切。因此,通过运行flask db init 命令为微博客创建迁移存储库:
(venv) D:\microblog>flask db init
Creating directory D:\microblog\migrations ... done
Creating directory D:\microblog\migrations\versions ... done
Generating D:\microblog\migrations\alembic.ini ... done
Generating D:\microblog\migrations\env.py ... done
Generating D:\microblog\migrations\README ... done
Generating D:\microblog\migrations\script.py.mako ... done
Please edit configuration/connection/logging settings in 'D:\\microblog\\migrations\\alembic.ini' before proceeding.运行完该命令后,项目文件夹microblog下新增migrations目录,它就是迁移目录,其中包含一些文件、一个版本子目录。从此刻开始,所有这些文件都应视为项目的一部分,且应该添加到源代码管理中。
flask命令是依赖于FLASK_APP环境变量来知道Flask应用程序的位置。对于这个应用程序,正是FLASK_APP = microblog.py。
6. 第1次数据库迁移
有了迁移存储库,就可创建第一个数据库迁移,其中包括映射到User数据库模型的users表。有两种方法可创建数据库迁移:手动、自动。为了自动生成迁移,Alembic将数据库模型定义的数据库模式与数据库中当前使用的实际数据库模式进行比较。然后,它会使迁移脚本填充必要的更改,以使数据库模式与应用程序模型匹配。在当前情况下,由于此前没有数据库,自动迁移会将整个User模型添加到迁移脚本中。flask db migrate子命令生成这些自动迁移:
(venv) D:\microblog>flask db migrate -m "users table"
INFO [alembic.runtime.migration] Context impl SQLiteImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [alembic.autogenerate.compare] Detected added table 'user'
INFO [alembic.autogenerate.compare] Detected added index 'ix_user_email' on '['email']'
INFO [alembic.autogenerate.compare] Detected added index 'ix_user_username' on '['username']'
Generating D:\microblog\migrations\versions\1f1d69541c8c_users_table.py ... doneflask db migrate -m "users table"将输出Alembic在迁移中包含的内容。前两行是信息性的,通常可忽略。接着,说检测到一个用户表、两个索引。最后,它告知编写的迁移脚本的位置。这个1f1d69541c8c_users_table.py文件(位于migrations\versions目录下)是用于迁移自动生成的唯一代码。使用-m选项提供注释的可选的,它可为迁移添加一个简短的描述性文本。
此时,microblog目录下将新增app.db文件(即SQLite数据库)、microblog\migrations\versions下1f1d69541c8c_users_table.py文件。生成的这个迁移脚本现已是项目的一部分,需要合并到源代码管理中。它里头有两个函数:upgrade()用于迁移;downgrade()用于删除。这允许Alembic使用降级路径将数据库迁移到历史记录的任何位置,甚至迁移到旧版本。
flask db migrate命令不对数据库进行任何更改,它只生成迁移脚本。要将更改运用于数据库,必须使用flask db upgrade命令。 因为这个应用程序使用SQLite,所以upgrade命令将检测数据库不存在,并将创建它。如果使用的是MySQL或PostgreSQL等数据库服务器,得在运行upgrade命令之前在数据库服务器创建数据库。
(venv) D:\microblog>flask db upgrade
INFO [alembic.runtime.migration] Context impl SQLiteImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [alembic.runtime.migration] Running upgrade -> 1f1d69541c8c, users table此时,microblog目录下的app.db将更新。
PS:默认情况下,Flask-SQLAlchemy对数据库表使用“snake case”命名约定。对于上述User模型,在数据库中相应的表将被命名为user。对于AddressAndPhone模型类,将会被命名为address_and_phone。如果想选择自己的表名,可在模型类中添加一个名为__tablename__的属性,并将其设置为一个字符串。
7. 数据库升级和降级工作流程
现在这个Flask应用程序还处于起步阶段,但讨论未来的数据库迁移策略并无坏处。如应用程序在开发机器上,而且还有一个副本部署到线上和正在使用的生产服务器上。
假设应用程序的下个版本需对模型进行更改,例如添加新表。如果没有迁移,则需要弄清楚如何在开发机器和再次在服务器上去改变数据库模式,这可能需要做很多的工作。
但是,通过数据库迁移的支持,在修改了应用程序的模型后,将会生成一个新的迁移脚本(flask db migrate),我们可能会检查它以确保自动生成做正确的事,然后将改变运用于开发数据库(flask db upgrade)。我们将迁移脚本添加到源代码管理、并提交它。
当准备将新版本的应用程序发布到生产服务器时,需做的是获取应用程序的更新版本(包括新的迁移脚本)并运行flask db upgrade。Alembic将检测到生产数据库未更新到最新版本的模式,并运行在先前版本之后创建的所有新迁移脚本。
flask db downgrade命令,可撤销上次迁移。虽然我们不太可能在生产系统上需要它,但可能在开发过程非常有用。例:已生成迁移脚本并将其运用,但发现所做的更改并非所需要的。这种情况下,可降级数据库,删除迁移脚本,然后生成一个新的替换它。
8. 数据库关系
关系数据库善于存储数据项之间的关系。考虑用户撰写博客文章的情况,用户将在users表中有一条记录,该帖子在posts表中也将有一条记录。记录撰写特定帖子的人最有效的方法是链接两个相关记录。
一旦建立了用户、帖子之间的链接,数据库就可以回答有关此链接的查询。最简单的一个查询:当有博客帖子并且知道需要知道用户写了什么。更复杂的查询与此相反:可能想知道某用户所写的所有帖子。Flask-SQLAlchemy将帮助处理这两种类型的查询。
扩展数据库以存储博客文章,并查看它们的关系。以下是新posts表的结构: 
这个posts表有id、body、timestamp字段。还有一个额外的字段user_id,将帖子连接到作者。所有用户都有一个主键id,是唯一的。将博客帖子链接到所创作它的用户的方法是添加对用户的引用id,这正是user_id字段,称之为 外键。上述图中显示了作为外键的字段 user_id与id字段之间的链接,这种关系称之为一对多,即一个用户可写多篇帖子。
更新models模块,app/models.py:帖子的数据库表和关系
from app import db
from datetime import datetime
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(64), index=True, unique=True)
email = db.Column(db.String(120), index=True, unique=True)
password_hash = db.Column(db.String(128))
posts = db.relationship('Post', backref='author', lazy='dynamic')
def __repr__(self):
return '<User {}>'.format(self.username)
class Post(db.Model):
id = db.Column(db.Integer, primary_key=True)
body = db.Column(db.String(140))
timestamp = db.Column(db.DateTime, index=True, default=datetime.utcnow)
user_id = db.Column(db.Integer, db.ForeignKey('user.id'))
def __repr__(self):
return '<Post {}'.format(self.body)新建的Post类表示用户撰写的博客文章。timestamp字段被 编入索引,比如按时间顺序检索帖子,这将非常有用;还添加了default参数,并传给它datetime.utcnow函数(得到的是格林威治时间 (GMT),即北京时间减8个时区的时间),在此,要注意一点,即将函数作为默认参数传递时,SQLAlchemy会将该字段设置为调用该函数的值(utcnow后没有括号()),传递的是函数本身,而不是调用它的结果。通常,在服务器应用程序中使用UTC日期和时间,这可确保使用统一的时间戳,无论用户立于何处,这些时间戳都可在显示时转换为用户的本地时间。 user_id字段已作为一个外键初始化了,这表明它引用了users表中的id值。在这个引用中user表示模型中数据库表的名称。这有一个不幸的不一致:在某些情况下,如db.relationship()调用中,模型由模型类引用,模型类通常以大写字符开头;而在其他情况下,如db.ForeignKey()中,模型由数据库表名称给出,SQLAlchemy自动使用小写字符,对于多字模型名称将使用“snake case”命名约定。
User类有一个新的posts字段,是用db.relationship初始化的。这不是一个真正的数据库字段,而是用户、帖子之间关系的高级视图,因此它不在数据库图中。对于一对多关系,db.relationship字段通常在“一”侧定义,并且用作访问“多”的便捷方式。因此,举例,如果有一个用户存储 u,表达式u.posts将运行一个数据库查询,返回该用户的所有帖子。db.relationship的第一个参数 表示关系“多”的模型类。如果模型稍后在模块中定义,则此参数可作为带有类名的字符串提供。第二个参数backref定义将添加到“多”类的对象的字段的名称,该类指向“一”对象。这将添加一个post.author表达式,它将返回给定帖子的用户。第三个参数lazy定义了如何发布对关系的数据库查询,这将在稍后讨论。
由于我们对应用程序的模型进行了更新,因此需要生成新的数据库迁移:
(venv) D:\microblog>flask db migrate -m "posts table"
INFO [alembic.runtime.migration] Context impl SQLiteImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [alembic.autogenerate.compare] Detected added table 'post'
INFO [alembic.autogenerate.compare] Detected added index 'ix_post_timestamp' on '['timestamp']'
Generating D:\microblog\migrations\versions\c0139b2ef594_posts_table.py ... done迁移需要应用于数据库:
(venv) D:\microblog>flask db upgrade
INFO [alembic.runtime.migration] Context impl SQLiteImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [alembic.runtime.migration] Running upgrade 1f1d69541c8c -> c0139b2ef594, posts table9. Show Time
上述所有内容均是讲述如何定义数据库,但还未告知如何运作的。由于应用程序还没有任何数据库逻辑,接下来将在Python解释器中使用数据库来熟悉它。在激活虚拟环境的前提下,启动Python解释器,进入Python提示后,导入数据库实例、模型:
(venv) D:\microblog>python
Python 3.6.3 (v3.6.3:2c5fed8, Oct 3 2017, 18:11:49) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> from app import db
>>> from app.models import User, Post首先,创建一个新用户:
>>> u = User(username='john', email='john@example.com')
>>> db.session.add(u)
>>> db.session.commit()对数据库的更改在会话session的上下文中完成,即作为db.session()访问。可以在会话session中累积多次更改,一旦所有的更改注册了,就可以用db.session.commit()发送一个信号,它以原子方式写入所有更改。 如果在会话session期间任何时间有一个错误,都可调用db.session.rollback()中止会话session并删除存储在其中的任何更改。 请注意的是:更改只会在db.session.commit()调用时写入数据库。会话session保证了数据库永远不会处于不一致状态。
添加另一个用户:
>>> u = User(username='susan', email='susan@example.com')
>>> db.session.add(u)
>>> db.session.commit()数据库可回答一个返回所有用户的查询:
>>> users = User.query.all()
>>> users
[<User john>, <User susan>]
>>> for u in users:
... print(u.id, u.username)
...
1 john
2 susan所有模型都有一个query属性,它是运行数据库查询的入口点。最基本的查询是返回该类的所有元素,它被适当地命名为all()。上述例中:这两个用户被添加时,id字段会被自动地设置为1和2。 如果知道用户id,还可通过如下方式检索该用户:
>>> u = User.query.get(1)
>>> u
<User john>为id 为1的用户添加一篇博文:
>>> u = User.query.get(1)
>>> p = Post(body='my first post come!', author=u)
>>> db.session.add(p)
>>> db.session.commit()不需要为timestamp字段设置值,因为它有默认值(模型中定义了)。对于user_id字段,User类向用户添加posts字段中db.relationship还把author属性给了帖子。这里使用author虚拟字段将作者分配给帖子,而不是必须处理用户ID。SQLAlchemy在这方面做的很好,它提供了对关系、外键的高级抽象。
再看几个数据库查询:
>>> #取得一个用户写的所有帖子
...
>>> u = User.query.get(1)
>>> u
<User john>
>>> posts = u.posts.all()
>>> posts
[<Post my first post come!]
>>> #同样,看看没有写帖子的用户
...
>>> u = User.query.get(2)
>>> u
<User susan>
>>> u.posts.all()
[]
>>> #对所有帖子打印其作者、内容
...
>>> posts = Post.query.all()
>>> for p in posts:
... print(p.id, p.author.username, p.body)
...
1 john my first post come!
>>> #以反字母顺序打印所有用户
...
>>> User.query.order_by(User.username.desc()).all()
[<User susan>, <User john>]Flask_SQLAlchemy文档可学习到更多查询数据库的知识。
删除上述创建的测试用户、帖子,以便数据库干净,并为下一章做准备:
>>> users = User.query.all()
>>> for u in users:
... db.session.delete(u)
...
>>> posts = Post.query.all()
>>> for p in posts:
... db.session.delete(p)
...
>>> db.session.commit()10. Shell上下文
在上一节开启Python解释器后,做的第一件事是运行一些导入:
>>> from app import db
>>> from app.models import User, Post在处理应用程序时,经常需要在Python shell中进行测试,如果每次都要重复上述导入,将变得极其乏味、麻烦。flask shell命令是flask命令伞中另一个非常有用的工具。shell命令是在run之后,Flask执行的第二个核心命令。这个命令的目的是在应用程序的上下文中启动Python解释器。以下示例助理解:
(venv) d:\microblog>python
Python 3.6.3 (v3.6.3:2c5fed8, Oct 3 2017, 18:11:49) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> app
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'app' is not defined
>>>exit()
(venv) d:\microblog>flask shell
Python 3.6.3 (v3.6.3:2c5fed8, Oct 3 2017, 18:11:49) [MSC v.1900 64 bit (AMD64)] on win32
App: app [production]
Instance: d:\microblog\instance
>>> app
<Flask 'app'>使用常规解释器会话(python)时,app符号除非显示导入了,否则它是不可知的,会报错!但是使用flask shell命令,它预先导入应用程序实例。flask shell的好处是:不是它预先导入app,而是我们可配置一个“shell context”(即shell上下文,它是一个预先导入的其他符号的列表)。
在模块microblog.py添加给函数,它创建了一个shell 上下文,将数据库实例、模型添加到shell会话中:
from app import app, db
from app.models import User, Post
@app.shell_context_processor
def make_shell_context():
return {'db': db, 'User': User, 'Post': Post}上述app.shell_context_processor装饰器注册了一个作为shell 上下文功能的函数。当运行flask shell命令时,它将调用此函数并在shell会话中注册它返回的项。函数返回字典而不是列表的原因是:对于每个项目,我们还须提供一个名称,在这个名称下,它将在shell中被引用,由字典的键给出。
由于上述更新了microblog.py文件,则必须重新设置FLASK_APP环境变量,否则会报错NameError。添加了shell 上下文处理器功能后,我们可以方便地使用数据库实体,而无需导入它们:
(venv) d:\microblog>set FLASK_APP=microblog.py
(venv) d:\microblog>flask shell
Python 3.6.3 (v3.6.3:2c5fed8, Oct 3 2017, 18:11:49) [MSC v.1900 64 bit (AMD64)] on win32
App: app [production]
Instance: d:\microblog\instance
>>> db
<SQLAlchemy engine=sqlite:///d:\microblog\app.db>
>>> User
<class 'app.models.User'>
>>> Post
<class 'app.models.Post'>目前为止,项目结构:
microblog/
app/
templates/
base.html
index.html
login.html
__init__.py
forms.py
models.py
routes.py
migrations/
venv/
app.db
config.py
microblog.py参考: https://blog.miguelgrinberg.com/post/the-flask-mega-tutorial-part-iv-database
10-flask博客项目实战五之用户登录功能
1.密码哈希
用户模型有一个password_hash字段,到目前为止尚未使用。它是用于保存用户密码的哈希值,密码用于验证用户在登录过程中输入的密码。密码散列是一个复杂的主题,应交给安全专家,但有几个易于使用的库以一种简单地从应用程序调用的方式实现所有逻辑。
其中一个实现密码散列的包是Werkzeug,在安装Flask,它已自动安装上了(虚拟环境中),因为是核心依赖之一。以下Python shell会话将演示如何散列密码:
(venv) d:\microblog>python
Python 3.6.3 (v3.6.3:2c5fed8, Oct 3 2017, 18:11:49) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> from werkzeug.security import generate_password_hash
>>> hash = generate_password_hash('foobar')
>>> hash
'pbkdf2:sha256:50000$G6lpo6G5$017b9bc06a89d2886a0cf255cb0db7ab34242cfcf7eb45900eade8cffe63f059'PS:退出python shell有两种方法:1)exit()或quit(),回车;2)Ctrl+Z后,回车。 上述示例中,密码 foobar 经过一系列没有已知的反向操作的加密操作,转换为长编码的字符串,这意味着获得散列密码的人无法用它来得到原始密码。作为一项额外措施,如果多次散列相同的密码,那么将得到不同的结果。因此,使得无法通过查看其哈希值来确定两个用户是否具有相同的密码。
验证过程得使用Werkzeug的第二个功能来完成,如下:
>>> from werkzeug.security import check_password_hash
>>> check_password_hash(hash, 'foobar')
True
>>> check_password_hash(hash, 'barfoo')
False验证函数check_password_hash()采用先前生成的密码哈希值和用户在登录时输入的密码。True表示用户输入的密码与哈希值匹配,否则返回False。
整个密码哈希逻辑在用户模型可作为两个新方法实现,更新代码: app/models.py:密码哈希、验证
from app import db
from datetime import datetime
from werkzeug.security import generate_password_hash,check_password_hash
class User(db.Model):
# ...
def __repr__(self):
return '<User {}>'.format(self.username)
def set_password(self, password):
self.password_hash = generate_password_hash(password)
def check_password(self, password):
return check_password_hash(self.password_hash, password)
# ...有了上述这俩个方法,一个用户对象现在就可以进行安全密码验证,而无需存储原始密码。以下是上述新方法的示例:
(venv) d:\microblog>flask shell
Python 3.6.3 (v3.6.3:2c5fed8, Oct 3 2017, 18:11:49) [MSC v.1900 64 bit (AMD64)] on win32
App: app [production]
Instance: d:\microblog\instance
>>> u = User(username='susan', email='susan@example.com')
>>> u.set_password('mypassword')
>>> u.check_password('anotherpassword')
False
>>> u.check_password('mypassword')
True2. Flask-Login简介
Flask-Login是非常流行Flask扩展。用于管理用户登录状态,以便做到诸如用户可登录到应用程序,然后在应用程序“记住”用户登录并导航到不同页面。它还提供“记住我”功能,即使是在关闭浏览器窗口后,用户也可保持登录状态。在虚拟环境中安装Flask-Login:版本0.4.1
(venv) d:\microblog>pip install flask-login
Collecting flask-login
Using cached https://files.pythonhosted.org/packages/c1/ff/bd9a4d2d81bf0c07d9e53e8cd3d675c56553719bbefd372df69bf1b3c1e4/Flask-Login-0.4.1.tar.gz
Requirement already satisfied: Flask in .\venv\lib\site-packages (from flask-login)
Requirement already satisfied: Werkzeug>=0.14 in .\venv\lib\site-packages (from Flask->flask-login)
Requirement already satisfied: click>=5.1 in .\venv\lib\site-packages (from Flask->flask-login)
Requirement already satisfied: Jinja2>=2.10 in .\venv\lib\site-packages (from Flask->flask-login)
Requirement already satisfied: itsdangerous>=0.24 in .\venv\lib\site-packages (from Flask->flask-login)
Requirement already satisfied: MarkupSafe>=0.23 in .\venv\lib\site-packages (from Jinja2>=2.10->Flask->flask-login)
Installing collected packages: flask-login
Running setup.py install for flask-login ... done
Successfully installed flask-login-0.4.1和其他扩展一样,需要在app/*init*.py中的应用程序实例之后立即创建和初始化Flask-Login。 app/*init*.py:Flask-Login初始化
# ...
from flask_login import LoginManager
app = Flask(__name__)
# ...
login = LoginManager(app)
# ...3. 为Flask-Login准备用户模型
Flask-Login扩展与应用程序的用户模型一起使用,并期望在其中实现某些属性和方法。这种做法很好,因为只要将将这些必需的项添加到模型中,Flask-Login就没有任何其他要求。因此,例如,它可以与基于任何数据系统的用户模型一起使用。
以下列出4个必需项目:
is_authenticated:一个属性,如果用户具有有效凭据则是True,否则是False。is_active:属性,如果用户的账户处于活动状态则是True;其他状态下是False。is_anonymous:属性,普通用户则是False;匿名用户则是True。get_id():一个方法,以字符串形式返回用户的唯一标识符。 我们可轻松地实现上述4个,但由于实现相当通用,Flask-Login提供了一个名为UserMixin的mixin类,它包含适用于大多数用户模型类的通用实现。以下将mixin类添加到模型中: app/models.py:添加Flask-Login用户mixin类
#...
from flask_login import UserMixin
class User(UserMixin, db.Model):
#...4. 用户加载器功能
Flask-Login通过在Flask的用户会话中存储其唯一的标识符来跟踪登录用户,这个用户会话是分配给连接到应用程序的每个用户的存储空间。每次登录用户导航到新页面时,Flask-Login都会从会话中检索用户的ID,然后将用户加载到内存中。
因为Flask-Login对数据库一无所知,所以在加载用户时需要应用程序的帮助。因此,扩展期望应用程序配置一个用户加载函数,它可以被调用去加载给定ID的用户。这个函数添加到app/models.py模块中: app/models.py:Flask-Login用户加载函数
from app import login
# ...
@login.user_loader
def load_user(id):
return User.query.get(int(id))
# ...使用@login.user_loader装饰器向Flask-Login注册用户加载函数。Flask-Login传递给函数的id作为一个参数将是一个字符串,所以需要将字符串类型转换为int型以供数据库使用数字ID。
5. 用户登录
这儿重新访问 登录视图 函数,那时现实了发出flash()消息的虚假登录。既然应用程序可访问用户数据库,并且知道如何生存、验证密码哈希,那么就可以完成视图功能。 app/routes.py:实现登录视图函数的逻辑
# ...
from flask_login import current_user, login_user
from app.models import User
# ...
@app.route('/login', methods=['GET', 'POST'])
def login():
if current_user.is_authenticated:
return redirect(url_for('index'))
form = LoginForm()
if form.validate_on_submit():
user = User.query.filter_by(username=form.username.data).first()
if user is None or not user.check_password(form.password.data):
flash('Invalid username or password')
return redirect(url_for('login'))
login_user(user, remember=form.remember_me.data)
return redirect(url_for('index'))
return render_template('login.html', title='Sign In', form=form)其中,login()函数的前两行处理了一个奇怪情况:想象一下,有一个登录用户,Ta导航到/login URL。显然这是错误的,不允许这么做。current_user变量来自Flask-Login,可在处理过程中随时使用,以表示请求客户端的用户对象。此变量的值可以是数据库中的用户的对象(Flask-Login通过上述提供的用户加载器回调读取的),如果用户尚未登录,则可以是特殊的匿名用户对象。回想一下用户对象需要Flask-Login的那4个项目(3个属性,1个方法),其中一个是 is_authenticated,它可以方便地检查用户是否登录。当用户已经登录时,只需重定向到/index页面。
代替之前的flash(),现在我们可以将用户登录为真实的。首先,从数据库加载用户。用户名来自于表单提交,因此我们可以使用查询来查找数据库以查找用户。为此,使用SQLAlchemy的filter_by()方法查询对象。得到的查询结果是只包含具有匹配用户名的对象。因为我们知道1个或0个结果,所以通过调用first()完成查询,如果存在则返回用户对象,否则返回None。调用all()将执行查询,得到查询匹配的所有结果的列表。当我们只需要一个结果时,通过使用first()方法执行查询。
如果我们得到了所提供用户名的匹配项,接下来则可以检查该表单附带的密码是否有效。这将通过调用check_password()方法完成。它将获取与用户一起存储的密码哈希值,并确定在表单输入的密码是否与哈希值匹配。因此,现在有两个可能的错误条件:用户名可能无效;或用户密码可能不正确。在任一情况下,都将flash一条消息,从重定向到登录页面,以便用户可以再次尝试。
如果用户名、密码都正确,那么将调用来自Flask-Login的login_user()函数。这个函数将在登录时注册用户,这意味着用户导航的任何未来页面都将current_user变量设置为该用户。
最后,要完成这个登录过程,只需将新登录的用户重定向到/index页面。
6. 用户退出
为用户提供退出应用程序的选项。这得使用Flask-Login的logout_user()函数完成,即退出视图函数: app/routes.py:退出视图函数
# ...
from flask_login import logout_user
#...
# ...
@app.route('/logout')
def logout():
logout_user()
return redirect(url_for('index'))要想用户公开此链接,可在用户登录后使用导航栏的“登录”链接自动切换到“退出”链接。通过base.html模板中的条件来完成,更新代码: app/templates/base.html:条件登录、退出链接
...
<div>
Microblog:
<a href="{{ url_for('index') }}">Home</a>
{% if current_user.is_anonymous %}
<a href="{{ url_for('login') }}">Login</a>
{% else %}
<a href="{{ url_for('logout') }}">Logout</a>
{% endif %}
</div>
...is_anonymous属性是Flask-Login通过UserMixin类添加到用户对象的属性之一。current_user.is_anonymous表达式将只在用户没有登录时为True。
7. 要求用户登录
Flask-Login还提供了一个非常有用的功能:强制用户在查看应用程序的某些页面之前必须登录。如果未登录用户尝试查看受保护的页面,Flask-Login将自动将用户重定向到登录表单,并且仅在登录过程完成后重定向回用户想要查看的页面。
要实现上述功能,Flask-Login需要知道处理登录的视图函数是什么。这可在app/*init*.py中添加:
# ...
login = LoginManager(app)
login.login_view = 'login'
#...上述‘login’的值是登录视图的函数(或端点)名称。也就是:在url_for()调用中使用的名称来获取URL。
Flask-Login为匿名用户保护视图函数的方式是 使用一个名为@login_required的装饰器。当将这个装饰器添加到来自Flask的@app.route的装饰器下方时,这个函数将被收到保护,并且不允许未经过身份验证的用户。下方是装饰器如何用于应用程序的index视图函数: app/routes.py:添加@login_required装饰器
#...
from flask_login import login_required
#...
@app.route('/')
@app.route('/index')
@login_required
def index():
# ...剩下的是实现:从成功登陆 到 用户想要访问的页面的重定向。当未登录用户访问受@login_required装饰器保护的视图函数时,装饰器将重定向到登录页面,但它将在此重定向中包含一些额外信息,以便应用程序可返回到第一个页。例如,如果用户到/index,@login_required装饰器将拦截请求,并使用重定向响应/login,但它会向此URL添加一个查询字符串参数,从而形成完成的重定向URL /login?next=/index。next 查询字符串参数设置为原始URL,因此应用程序可使用这个参数在登录后重定向。 下方代码将展示如何读取、处理 next查询字符串参数: app/routes.py:重定向到 next 页面
from flask import request
from werkzeug.urls import url_parse
#...
@app.route('/login', methods=['GET', 'POST'])
def login():
# ...
if form.validate_on_submit():
user = User.query.filter_by(username=form.username.data).first()
if user is None or not user.check_password(form.password.data):
flash('Invalid username or password')
return redirect(url_for('login'))
login_user(user, remember=form.remember_me.data)
#重定向到 next 页面
next_page = request.args.get('next')
if not next_page or url_parse(next_page).netloc != '':
next_page = url_for('index')
return redirect(next_page)
return render_template('login.html',title='Sign In',form=form)
# ...在用户通过调用Flask-Login的login_user()函数登录后,获取next查询字符串参数的值。这里写代码片Flask提供了一个request变量,它包含客户端随 请求 发送的所有信息。特别的是,request.args属性以友好的字典格式公开查询字符串的内容。实际上,在成功登录后,确实需要考虑三种可能的情况来确定重定向的位置:
- 如果登录URL没有
next参数,则将页面重定向到/index页面。 - 如果登录URL包含
next设置为相对路径的参数(即没有域部分的URL),则将用户重定向到该URL。 - 如果登录URL包含
next设置为包含域名的完整URL的参数,则将用户重定向到/index页面。
上述第1、2种情况很明显。第3种情况是为让应用程序更安全。攻击者可在next参数中插入恶意站点的URL,因此应用程序仅在URL为相对时重定向,这可确保重定向与应用程序保持在同一站点内。要确定URL是相对的、还是绝对的,要使用Werkzeug的url_parse()函数解析它,然后检查netloc组件是否已设置。
8. 在模板中显示登录用户
以前,创建过“假”用户来设计应用程序主页,因为那时没有用户系统。现在我们可以有真正的用户了,就可以删除“假”用户了,用真实用户了。修改index.html模板代码,使用Flask-Login的current_user替换“假”用户: app/templates/index.html:将当前用户传递给模板
{% extends "base.html" %}
{% block content %}
<h1>Hello,{{ current_user.username }}!</h1>
{% for post in posts %}
<div><p>{{ post.author.username }} says: <b>{{ post.body }}</b></p></div>
{% endfor %}
{% endblock %}并在视图函数中删除这个user模板参数:修改代码 app/routes.py:不再将用户传递给模板
#...
@app.route('/')
@app.route('/index')
@login_required
def index():
posts = [
{
'author': {'username': 'John'},
'body': 'Beautiful day in Portland!'
},
{
'author': {'username': 'Susan'},
'body': 'The Avengers movie was so cool!'
}
]
return render_template('index.html', title='Home', posts=posts)
#...目前为止,就能测试:登录、退出功能了。不过暂无用户注册功能,得通过将用户添加到数据库,即用Python shell操作,运行flask shell命令,并输入以下命令来向数据库添加用户:
C:\Users\Administrator>d:
D:\>cd D:\microblog\venv\Scripts
D:\microblog\venv\Scripts>activate
(venv) D:\microblog\venv\Scripts>cd D:\microblog
(venv) D:\microblog>set FLASK_APP=microblog.py
(venv) D:\microblog>flask shell
Python 3.6.3 (v3.6.3:2c5fed8, Oct 3 2017, 18:11:49) [MSC v.1900 64 bit (AMD64)] on win32
App: app [production]
Instance: D:\microblog\instance
>>> u = User(username='susan', email='susan@example.com')
>>> u.set_password('cat')
>>> db.session.add(u)
>>> db.session.commit()先退出上述Python shell,运行程序:
>>> quit()
(venv) D:\microblog>flask run
* Serving Flask app "microblog.py"
* Environment: production
WARNING: Do not use the development server in a production environment.
Use a production WSGI server instead.
* Debug mode: off
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
...浏览器访问http://localhost:5000/或http://localhost:5000 /index,都将立即重定向到 /login登录页面。在使用刚才添加到数据库中的用户名、密码登录后,将返回到原始页面,并将看到个性化问候语。效果:

登录后 
点击“Logout”按钮,即可退出用户登录,重定向到登录页面。
9. 用户注册
构建本章最后一项功能:用户注册表单。以便用户可以通过Web表单进行注册。首先,在app/forms.py中创建Web表单类: app/forms.py
from flask_wtf import FlaskForm
from wtforms import StringField, PasswordField, BooleanField, SubmitField
from wtforms.validators import ValidationError, DataRequired, Email, EqualTo
from app.models import User
# ...
class RegistrationForm(FlaskForm):
username = StringField('Username', validators=[DataRequired()])
email = StringField('Email', validators=[DataRequired(), Email()])
password = PasswordField('Password', validators=[DataRequired()])
password2 = PasswordField(
'Repeat Password', validators=[DataRequired(), EqualTo('password')])
submit = SubmitField('Register')
def validate_username(self, username):
user = User.query.filter_by(username=username.data).first()
if user is not None:
raise ValidationError('Please use a different username.')
def validate_email(self, email):
user = User.query.filter_by(email=email.data).first()
if user is not None:
raise ValidationError('Please use a different email address.')这个与验证相关的新表格中有一些有趣的东西。首先,在email字段,在添加了DataRequired验证器后,还添加了第二个验证器Email。它是WTForms附带的另一个stock validator,它将确保用户在此字段中键入的内容与电子邮件地址的结构相匹配(省了正则去匹配这是否为一个邮箱地址)。
因为这是个注册表单,因此通常都会要求用户输入密码两次以减少拼写错误的风险。因此,用了password、password2两个字段。第二个字段 用了另一个stock validator EqualTo,它将确保其值与第一个密码字段的值相同。
还为这个类添加两个方法:validate_username()、validate_email()。当添加与模式匹配任何 validate_字段名方法时,WTForms会将这些方法作为自定义验证器,并在stock validator之外调用它们。在这种情况下,确定用户输入的用户名、电子邮件地址是否在数据库中,因此这俩个方法会发出数据库查询。如果存在查询结果,则通过触发验证错误ValidationError。将在字段傍边显示包含此异常的消息让用户查看。
要在网页上显示这个Web表单,还需一个HTML模板,存于app/templates/register.html中,此模板的构造类似于登录表单的模板: app/templates/register.html:用户注册模板
{% extends "base.html" %}
{% block content %}
<h1>Register</h1>
<form action="" method="post">
{{ form.hidden_tag() }}
<p>
{{ form.username.label }}<br>
{{ form.username(size=32) }}<br>
{% for error in form.username.errors %}
<span style="color:red;">[{{ error }}]</span>
{% endfor %}
</p>
<p>
{{ form.email.label }}<br>
{{ form.email(size=64) }}<br>
{% for error in form.email.error %}
<span style="color:red;">[{{ error }}]</span>
{% endfor %}
</p>
<p>
{{ form.password.label }}<br>
{{ form.password(size=32) }}<br>
{% for error in form.password.errors %}
<span style="color:red;">[{{ error }}]</span>
{% endfor %}
</p>
<p>
{{ form.password2.label }}<br>
{{ form.password2(size=32) }}<br>
{% for error in form.password2.errors %}
<span style="color:red;">[{{ error }}]</span>
{% endfor %}
</p>
<p>{{ form.submit() }}</p>
</form>
{% endblock %}登录表单模板需要一个链接,用于发送新用户到注册表单,位于登录表单下方: app/templates/login.html:链接到注册页面
#...
<p>{{ form.submit() }}</p>
</form>
<p>New User? <a href="{{ url_for('register') }}">Click to Register!</a></p>
{% endblock %}最后,在app/routes.py中编写处理用户注册的视图函数: app/routes.py:用户注册视图函数
#...
from app import db
from app.forms import RegistrationForm
#...
# ...
@app.route('/register', methods=['GET', 'POST'])
def register():
if current_user.is_authenticated:
return redirect(url_for('index'))
form = RegistrationForm()
if form.validate_on_submit():
user = User(username=form.username.data, email=form.email.data)
user.set_password(form.password.data)
db.session.add(user)
db.session.commit()
flash('Congratulations, you are now a registered user!')
return redirect(url_for('login'))
return render_template('register.html', title='Register', form=form)首先,确定调用此路由的用户未登录。表单的处理方式与登录的相同。在if validate_on_submit()判断内完成以下逻辑:创建一个新用户,其中提供用户名、电子邮件地址、密码,将其写入数据库,最后重定向到登录页面,以便用户登录。运行程序,效果:
(venv) D:\microblog>flask run
* Serving Flask app "microblog.py"
* Environment: production
WARNING: Do not use the development server in a production environment.
Use a production WSGI server instead.
* Debug mode: off
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
注册信息如:belen,belen@example.com,Abc123456 点击**“Register”**按钮,页面转向登录页面: 
点击**“Sign In”**按钮,页面转向/index页面。
至此,应用程序有了:创建账户、登录、退出的功能。在接下来的章节中,将重新访问用户身份验证子系统,以添加其他功能,如允许用户在忘记密码时重置密码。
仅修改app/models.py中User类的__repr__()代码,以便打印出数据库中 所有用户的信息:
#...
posts = db.relationship('Post', backref='author', lazy='dynamic')
def __repr__(self):
#return '<User {}>'.format(self.username)
return '<User {}, Email {}, Password_Hash {}, Posts {}'.format(self.username, self.email, self.password_hash, self.posts)
#...运行flask shell命令后,就可看到刚才注册的用户 belen。
(venv) D:\microblog>flask shell
Python 3.6.3 (v3.6.3:2c5fed8, Oct 3 2017, 18:11:49) [MSC v.1900 64 bit (AMD64)] on win32
App: app [production]
Instance: D:\microblog\instance
>>> u = User.query.all()
>>> u
[<User susan, Email susan@example.com, Password_Hash pbkdf2:sha256:50000$OONOkVyy$8d008c6647ab95a5793cf60bf57eaa3bb1123d6e5b3135c5cc5e42e02eddae32, Posts SELECT post.id AS post_id, post.body AS post_body, post.timestamp AS post_timestamp, post.user_id AS post_user_id
FROM post
WHERE ? = post.user_id, <User belen, Email belen@example.com, Password_Hash pbkdf2:sha256:50000$PEDt5NxS$cf6c958c97b6ad28d9495d138cb5a310f6f2389534b0cafa3002dd3cec9af9d1, Posts SELECT post.id AS post_id, post.body AS post_body, post.timestamp AS post_timestamp, post.user_id AS post_user_id
FROM post
WHERE ? = post.user_id]目前为止,项目结构:
microblog/
app/
templates/
base.html
index.html
login.html
register.html
__init__.py
forms.py
models.py
routes.py
migrations/
venv/
app.db
config.py
microblog.py参考 https://blog.miguelgrinberg.com/post/the-flask-mega-tutorial-part-v-user-logins
11-flask博客项目实战六之用户个人资料
本章将专门用于给应用程序添加用户个人资料页面。用户个人资料页面呈现的是关于用户信息的页面,通常具有由用户自己输入的信息。接下来将展示如何动态生成用户个人资料页面,然后添加一个小型个人资料编辑器,用户可用它来输入Ta们的信息。
1. 用户个人资料页面
要创建一个用户个人资料页面,首先编写一个映射到 /user/<username>URL的新视图函数。
app/routes.py:用户个人资料的视图函数
#...
@app.route('/user/<username>')
@login_required
def user(username):
user = User.query.filter_by(username=username).first_or_404()
posts = [
{'author':user, 'body':'Test post #1'},
{'author':user, 'body':'Test post #2'}
]
return render_template('user.html', user=user, posts=posts)这个由@app.route装饰器下声明的视图函数看起来与前面的有点不同。在这个示例下,有一个动态组件,它被作为<username>URL组件 表示,并由 <和>包围。当路由有动态组件时,Flask将接受URL部分中的任何文本,并将以实际文本作为参数调用视图函数。例如,如果客户端浏览器请求这个URL /user/susan,则将调用视图函数并将参数username 设置为susan。这个视图函数只能由登录用户访问,因此添加了Flask-Login的@login_required装饰器。
这个视图函数的实现非常简单。首先,尝试用username查询从数据库加载用户。在之前学过,假如想获得所有结果,可调用all()执行数据库查询;假如想获得第一个结果 或None(0个结果时),可调用first()执行数据库查询。在这个视图函数中,使用了一个叫first_or_404()的first()变体,在有结果的情况下它与first()完全一样,不过在没有结果的情况下,会自动将404 error发送回客户端。以这种方式执行查询,不用检查查询是否返回一个用户,因为数据库中不存在username时,函数将不会返回,而是会引发404异常。
如果数据库查询没有触发404 error,那么表示找到给定username的用户。接下来, 为用户初始化一个“假”的帖子列表,最后渲染一个新的user.html模板,将该模板传递给用户对象、帖子列表。 app/templates/user.html:用户个人资料模板
{% extends "base.html" %}
{% blcok content %}
<h1>User:{{ user.username }}</h1>
<hr>
{% for post in posts %}
<p>
{{ post.author.username }} says:<b>{{ post.body }}</b>
</p>
{% endfor%}
{% endblock%}个人资料页面已完成,但网站的任何位置都没有指向该页面的链接。为了让用户更容易检查自己的个人资料,将在顶部导航栏添加一个链接: app/templates/base.html:用户个人资料模板
<div>Microblog:
<a href="{{ url_for('index') }}">Home</a>
{% if current_user.is_anonymous %}
<a href="{{ url_for('login') }}">Login</a>
{% else %}
<a href="{{ url_for('user', username=current_user.username) }}">Profile</a>
<a href="{{ url_for('logout') }}">Logout</a>
{% endif %}
</div>上述唯一有趣的变化是用于生成个人资料页面链接的url_for()调用。由于用户个人资料视图函数采用动态参数,因此url_for()函数接收其值作为关键字参数。因为这是指向登录用户的个人资料的链接,所以使用Flask-Login的current_user生成正确的URL。 运行程序,效果:
(venv) D:\microblog>flask run
* Serving Flask app "microblog.py"
* Environment: production
WARNING: Do not use the development server in a production environment.
Use a production WSGI server instead.
* Debug mode: off
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
127.0.0.1 - - [10/Aug/2018 18:04:30] "GET /user/belen HTTP/1.1" 200 -
127.0.0.1 - - [10/Aug/2018 18:04:38] "GET /user/susan HTTP/1.1" 200 -当前数据库里有两个用户:susan、belen。改变URL /user/<username>将得到不同的页面;单击“Profile”按钮将转到登录用户的用户页面。但键入数据库中没有的username时,将得404页面。 
2. 用户头像
目前为止,建立的个人资料页面很单调。增加用户头像,但不打算在服务器中处理大量上传的图像,将使用Gravatar服务未所有用户提供图像。
Gravatar服务器使用起来很简单。要为给定用户请求图像,格式为 *https://www.gravatar.com/avatar/*的URL,其中是用户电子有地址的MD5哈希值。下方展示如何通过电子邮件获取使用`john@example.com`的用户的Gravatar URL:
(venv) D:\microblog>python
Python 3.6.3 (v3.6.3:2c5fed8, Oct 3 2017, 18:11:49) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> from hashlib import md5
>>> 'https://www.gravatar.com/avatar/' + md5(b'john@example.com').hexdigest()
'22861789757368.jpg'浏览器输入上述URL https://www.gravatar.com/avatar/d4c74594d841139328695756648b6bd6
将显示 
我的实例,Gravatar URL是 https://s.gravatar.com/avatar/9aefdb9ccdb72aa75ccbe1b921f9d9f2?s=80
返回的头像是: 
默认情况下,返回的图形大小为80x80像素,但可通过向URL的查询字符串添加 s 参数来请求不同大小的尺寸。例如,要获取一个128x128像素的图像,URL为 https://www.gravatar.com/avatar/d4c74594d841139328695756648b6bd6?s=128
另一个有趣的参数是 d,它能确定在服务中没有头像注册的用户由Gravatar提供图像。如作者喜欢的“identicon”,它为每个电子邮件返回一个不同的几何设计。如: 
PS:某些Web浏览器扩展程序(如 Ghostery会阻止Gravatar图像)因为它们会认为Automattic(Gravatar服务的所有者)可以根据它们为您的头像获取的请求来确定访问的网站。如果在浏览器中没有看到头像,可考虑的问题是 可能由于在浏览器中安装了某个扩展程序。
由于头像与用户相关联,因此将生成头像的URL的逻辑添加到User 用户模型中是很重要的。
from hashlib import md5
# ...
class User(UserMixin, db.Model):
# ...
def avatar(self, size):
digest = md5(self.email.lower().encode('utf-8')).hexdigest()
return 'https://www.gravatar.com/avatar/{}?d=identicon&s={}'.format(
digest, size)User类的新方法avatar()返回用户头像的URL,并缩放到请求的大小(以像素为单位)。对于没有注册头像的用户,将生成“identicon”图像。要生成MD5哈希,首先将电子邮件地址转换为小写,这是Gravatar服务要求的;然后,因为Python中的MD5支持字节而不是字符串,所以得在字符串传递给哈希函数之前,将字符串编码为字节。 参考:Gravatar服务文档
接下来,在用户个人资料模板中插入头像图像: app/templates/user.html:模板中的用户头像
{% extends "base.html" %}
{% block content %}
<table>
<tr valign="top">
<td><img src="{{ user.avatar(128) }}"></td>
<td><h1>User: {{ user.username }}</h1></td>
</tr>
</table>
<hr>
{% for post in posts %}
<p>
{{ post.author.username }} says: <b>{{ post.body }}</b>
</p>
{% endfor %}
{% endblock %}让User类负责返回头像URL的好处是:如果将来某些决定不需要Gravatar头像了,可重写avatar()方法以返回不同的URL,并且所有模板将开始自动显示新头像。
上述代码完成了在用户个人资料的顶部有一个大头像。还可为每个帖子得有个小头像,而且对于用户个人资料页面的所有帖子得是相同的头像。并且可在主页上实现相同的功能,然后每个帖子都将用作者的头像进行装饰。修改代码: app/templates/user.html:帖子中的用户头像
{% extends "base.html" %}
{% block content %}
<table>
<tr valign="top">
<td><img src="{{ user.avatar(128) }}"></td>
<td><h1>User:{{ user.username }}</h1></td>
</tr>
</table>
<hr>
{% for post in posts %}
<table>
<tr valign="top">
<td><img src="{{ post.author.avatar(36) }}"></td>
<td>{{ post.author.username }} says:<br>{{ post.body }}</td>
</tr>
</table>
{% endfor%}
{% endblock%}运行程序,效果:
(venv) D:\microblog>flask run
* Serving Flask app "microblog.py"
* Environment: production
WARNING: Do not use the development server in a production environment.
Use a production WSGI server instead.
* Debug mode: off
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
127.0.0.1 - - [10/Aug/2018 19:34:34] "GET /user/belen HTTP/1.1" 200 -
3. 使用Jinja2子模板
上述设计了用户个人资料页面,以便显示用户写的帖子、头像。如今,希望/index页面也显示具有类似布局的帖子。如果复制、粘贴处理帖子渲染的模板部分,这是不理想的,因为今后如果决定对这个布局进行更改,则一定要同时更新这两个模板。
理想方法:创建一个只渲染一个帖子的子模板,然后从user.html、index.html模板中引用它。首先,创建子模板,只需要一个帖子HTML标记。将此模板命名为app/templates/_post.html,其中_前缀只是个命名约定,用于识别该模板文件是子模板。 app/templates/_post.html:帖子子模板
<table>
<tr valign="top">
<td><img src="{{ post.author.avatar(36) }}"></td>
<td>{{ post.author.username }} says:<br>{{ post.body }}</td>
</tr>
</table>要从user.html模板调用此子模板,得使用Jinja2include语句:更新代码 app/templates/user.html:帖子中的用户头像
{% extends "base.html" %}
{% block content %}
<table>
<tr valign="top">
<td><img src="{{ user.avatar(128) }}"></td>
<td><h1>User: {{ user.username }}</h1></td>
</tr>
</table>
<hr>
{% for post in posts %}
{% include '_post.html' %}
{% endfor %}
{% endblock %}运行程序,效果是一样的: 
PS:目前应用程序的 /index页面还未真正充实,暂不添加此功能。
4. 更多有趣的个人资料
新用户个人资料页面有一个问题是Ta们并没有真正展现出太多。用户喜欢在这些页面上讲一些关于Ta们的内容,所以讲让Ta们写一些关于Ta们自己内容展示在这里。还将跟踪每个用户最后一次访问该网站的时间,并显示在Ta们的个人资料页面上显示。
要做的第一件事是支持所有这些额外信息,即用两个新字段扩展数据库中的users表: app/models.py:在用户模型中添加新字段
class User(UserMixin, db.Model):
# ...
about_me = db.Column(db.String(140))
last_seen = db.Column(db.DateTime, default=datetime.utcnow)
#...**每次修改数据库时,都必须生成数据库迁移。**在第4章,展示了如何设置应用程序以通过迁移脚本跟踪数据库更改。上述,有两个要添加到数据库的新字段,因此第一步是生成迁移脚本:
C:\Users\Administrator>d:
D:\>cd D:\microblog\venv\Scripts
D:\microblog\venv\Scripts>activate
(venv) D:\microblog\venv\Scripts>cd D:\microblog
(venv) D:\microblog>flask db migrate -m "new fields in user model"
INFO [alembic.runtime.migration] Context impl SQLiteImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [alembic.autogenerate.compare] Detected added column 'user.about_me'
INFO [alembic.autogenerate.compare] Detected added column 'user.last_seen'
Generating D:\microblog\migrations\versions\00cd8a8ea68a_new_fields_in_user_model.py ... done可注意到一个细节,-m参数的描述内容会自动添加到/versions下的迁移.p文件名中。
migrate命令的打印很友好,如显示了User类中两个新字段被检测到。现在可将这个更改运用于数据库:
(venv) D:\microblog>flask db upgrade
INFO [alembic.runtime.migration] Context impl SQLiteImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [alembic.runtime.migration] Running upgrade c0139b2ef594 -> 00cd8a8ea68a, new fields in user model使用迁移框架非常有用,数据库中的任何用户仍然存在,迁移框架通过“外科手术”运用迁移脚本中的更改而不会破坏任何数据。在CMD下命令行查看数据库中表结构:
(venv) D:\microblog>sqlite3 app.db #进入数据库
SQLite version 3.16.2 2017-01-06 16:32:41
Enter ".help" for usage hints.
sqlite> .tables #查看数据库中的表
alembic_version post user
sqlite> .schema user #查看表结构
CREATE TABLE user (
id INTEGER NOT NULL,
username VARCHAR(64),
email VARCHAR(120),
password_hash VARCHAR(128), about_me VARCHAR(140), last_seen DATETIME,
PRIMARY KEY (id)
);
CREATE UNIQUE INDEX ix_user_email ON user (email);
CREATE UNIQUE INDEX ix_user_username ON user (username);
sqlite> select * from user;#查看user表数据
1|susan|susan@example.com|pbkdf2:sha256:50000$OONOkVyy$8d008c6647ab95a5793cf60bf57eaa3bb1123d6e5b3135c5cc5e42e02eddae32||
2|belen|belen@example.com|pbkdf2:sha256:50000$PEDt5NxS$cf6c958c97b6ad28d9495d138cb5a310f6f2389534b0cafa3002dd3cec9af9d1||
sqlite> .quit #退出sqlite语句
(venv) D:\microblog>接着,将这俩个新字段添加到用户个人资料模板中: app/templates/user.html:在用户个人资料模板中显示用户信息
{% extends "base.html" %}
{% block content %}
<table>
<tr valign="top">
<td><img src="{{ user.avatar(128) }}"></td>
<td>
<h1>User:{{ user.username }}</h1>
{% if user.about_me %}
<p>{{ user.about_me }}</p>
{% endif %}
{% if user.last_seen %}
<p>Last seen on:{{ user.last_seen }}</p>
{% endif %}
</td>
</tr>
</table>
<hr>
{% for post in posts %}
{% include '_post.html' %}
{% endfor%}
{% endblock%}注意:这两个字段包装在Jinja2的条件中,因为只希望Ta们在设置时可见。此时对于所有用户,这俩个新字段都是空的,因此,如果现在运行该应用程序,不会看到这些字段。
5. 记录用户上次访问时间
last_seen这个字段相对更容易。现在要做的是:在用户向服务器发送请求时,为给定用户写入此字段的当前时间。
在从浏览器请求的每一个可能的视图函数中,添加登录去设置这个字段,这明显是不切实际的。请求分派到视图函数之前执行一些通用逻辑,这在Web应用程序中是一个常见任务,Flask将它作为一个原生特征提供。解决方案: app/routes.py:记录上次访问的时间
from datetime import datetime
#...
@app.before_request
def before_request():
if current_user.is_authenticated:
current_user.last_seen = datetime.utcnow()
db.session.commit()
#...Flask的@before_request装饰器在视图函数之前注册将要执行的装饰函数。这非常有用,因为现在可以在应用程序中的任何视图函数之前插入想要执行的代码,并可将它放在一个地方。 实现只是检查current_user是否已登录,并在这种情况下将last_seen字段设置为当前时间。 之前有提到,服务器应用程序需要以一致的时间单位工作,标准做法是使用UTC时区。使用系统的本地时间不是一个好办法,因为数据库中的内容取决于你的位置。 最后一步是提交数据库会话,以便将上面所做的更改写入数据库。
在提交之前,想知道为什么没有db.session.add(),得考虑什么时候引用current_user,Flask-Login将调用用户加载器回调函数,该函数将允许数据库查询,将目标用户置于数据库会话中。因此,可在此功能中再次添加用户,但这不是必需的,因为它已经存在了。
如果在做了这个更改后查看某个用户个人资料页面,那么将看到“Last seen on”行,其时间非常接近当前时间。而如果离开个人资料页面,再次返回,将看到时间更新。
实际上,我们将这些时间戳存储在UTC时区中,使得在个人资料页面显示的时间也是UTC。除此以外,时间格式不是所期望的,因为它实际是Python日期时间对象的内部表示。目前,不考虑这些问题,在今后的章节中讨论Web应用程序的日期和时间的话题。
运行程序,登录(用户名1+密码:belen,Abc123456;用户2:susan,cat )这个用户后,点击“Profile”,效果:
(venv) D:\microblog>flask run
* Environment: production
WARNING: Do not use the development server in a production environment.
Use a production WSGI server instead.
* Debug mode: off
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
6. 个人资料编辑
想用户提供一个表格,在表格中用户可输入一些关于Ta们自己的信息。这个表单允许用户修改用户名,并编写有关自己的内容,以存储在新about_me字段中。编写要给表单类:app/forms.py:个人资料编辑表单
#...
from wtforms import StringField, TextAreaField, SubmitField
from wtforms.validators import DataRequired, Length
#...
class EditProfileForm(FlaskForm):
username = StringField('Username', validators=[DataRequired()])
about_me = TextAreaField('About_me', validators=[Length(min=0, max=140)])
submit = SubmitField('Submit')about_me字段用的是TextAreaField,是一个多行框,用户可以在这输入文本。用Length验证这个字段,确保输入的文本在0-140个字符之间,这也是为数据库中相应字段分配的空间。
渲染上述表单的模板: app/templates/edit_profile.html:个人资料编辑 表单
{% extends "base.html" %}
{% block content %}
<h1>Edit Profile</h1>
<form action="", method="post">
{{ form.hidden_tag() }}
<p>
{{ form.username.label }}<br>
{{ form.username(size=32) }}<br>
{% for error in form.username.errors %}
<span style="color:red;">[{{ error }}]</span>
{% endfor %}
</p>
<p>
{{ form.about_me.label }}<br>
{{ form.about_me(cols=50, rows=4) }}<br>
{% for error in form.about_me.errors %}
<span style="color:red;">[{{ error }}]</span>
{% endfor %}
</p>
<p>
{{ form.submit() }}
</p>
</form>
}
{% endblock %}最后,完善视图函数,它将所有内容联系在一起: app/routes.py:编辑个人资料的视图函数
#...
from app.forms import EditProfileForm
#...
@app.route('/edit_profile',methods=['GET','POST'])
@login_required
def edit_profile():
form = EditProfileForm()
if form.validate_on_submit():
current_user.username = form.username.data
current_user.about_me = form.about_me.data
db.session.commit()
flash('Your changes have been saved.')
return redirect(url_for('edit_profile'))
elif request.method == 'GET':
form.username.data = current_user.username
form.about_me.data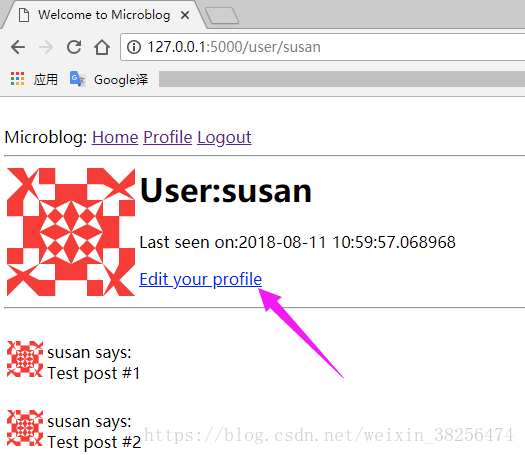 = current_user.about_me
return render_template('edit_profile.html', title='Edit Profile', form=form)这个视图函数与处理表单的其他函数略有不同。如果validate_on_submit()返回True,则将表单中的数据复制到用户对象中,然后将对象写入数据库;返回False,可能是由于两个不同的原因。首先,可能是因为浏览器刚发送了一个GET请求,需要通过提供表单模板的初始版本来响应。也可能是当浏览器发送带有表单数据的POST请求时,该数据中的某些内容无效。对于这种形式,需要分别处理这两种情况。当第一次以GET请求表格时,想用数据库中已存储的数据预先填充字段,所以得做与提交情况相反的操作,并将存储在用户字段中的数据移动到表单中,因为这将确保这些表单字段具有为用户存储的当前数据。但在验证错误的情况下,我们不想在表单字段中写入任何内容,因为这些已由WTForms填充。为区分这两种情况,得检查request.method,对初始化请求这将是GET,并对验证失败的提交将是POST。
为方便用户访问个人资料编辑页面,可在Ta们个人资料页面中添加一个链接: app/templates/user.html:添加个人资料编辑的链接
{% if user.last_seen %}
<p>Last seen on:{{ user.last_seen }}</p>
{% endif %}
{% if user == current_user %}
<p>
<a href="{{ url_for('edit_profile') }}">Edit your profile</a>
</p>
{% endif %}上述代码中加了个判断:当在查看自己个人资料时,显示编辑链接;在查看其他人资料时,不显示编辑链接。 运行程序 flask run ,效果: 
点击“Edit your profile”链接后,可看见 用户个人资料 编辑页面: 
点击“Submit”按钮后,会提示“Your changes have been saved.”,点击“Profile”链接后,效果: 
CMD下命令行查看 数据库中 user表信息,可看到新插入的字段内容:
(venv) D:\microblog>sqlite3 app.db
SQLite version 3.16.2 2017-01-06 16:32:41
Enter ".help" for usage hints.
sqlite> select * from user;
1|susan|susan@example.com|pbkdf2:sha256:50000$OONOkVyy$8d008c6647ab95a5793cf60bf57eaa3bb1123d6e5b3135c5cc5e42e02eddae32||2018-08-11 11:02:54.902074
2|belen|belen@example.com|pbkdf2:sha256:50000$PEDt5NxS$cf6c958c97b6ad28d9495d138cb5a310f6f2389534b0cafa3002dd3cec9af9d1|学习Flask超级教程,Python Web开发学习,坚持!|2018-08-11 11:21:03.778628目前为止,项目结构
microblog/
app/
templates/
_post.html
base.html
edit_profile.html
index.html
login.html
register.html
user.html
__init__.py
forms.py
models.py
routes.py
migrations/
venv/
app.db
config.py
microblog.py参考: https://blog.miguelgrinberg.com/post/the-flask-mega-tutorial-part-vi-profile-page-and-avatars
12-flask博客项目实战七之错误处理
本章将学习到:如何在Flask应用程序中进行错误处理(策略)。
这里将暂时停止为microblog添加新功能,而是讨论处理bug的策略,因为它们可能总是无处不在。为了帮助说明此主题,故意在上一节的代码中遗留一个bug。等待着我们去发现它。
1. 在Flask中的错误处理
在Flask应用程序中发生error时会发生什么?找到问题的最佳方法是亲自体验,即重现它。启动应用程序,并确保已有两个注册用户。用其中一个用户身份登录后(在此以用户名+密码 susan cat为例),打开【Profile】页面并点击【Edit you profile】链接。在个人资料编辑页面,尝试将用户名更改为已注册的另一个用户的用户名(以 belen为例)并提交,这将带来一个可怕的“Internal Server Error”页面: 

在cmd里的打印(即运行应用程序的终端会话),将看到这个Error的堆栈跟踪(stack trace)。它在调试Error时很有用,因为它们会显示这个堆栈中的调用序列,一直到产生Error的行:
(venv) D:\microblog>flask run
* Environment: production
WARNING: Do not use the development server in a production environment.
Use a production WSGI server instead.
* Debug mode: off
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
127.0.0.1 - - [13/Aug/2018 14:26:04] "GET /login?next=%2Fedit_profile HTTP/1.1" 200 -
127.0.0.1 - - [13/Aug/2018 14:26:08] "GET /login HTTP/1.1" 200 -
127.0.0.1 - - [13/Aug/2018 14:26:17] "POST /login HTTP/1.1" 302 -
127.0.0.1 - - [13/Aug/2018 14:26:17] "GET /index HTTP/1.1" 200 -
127.0.0.1 - - [13/Aug/2018 14:26:50] "GET /user/susan HTTP/1.1" 200 -
127.0.0.1 - - [13/Aug/2018 14:27:24] "GET /edit_profile HTTP/1.1" 200 -
[2018-08-13 14:28:45,549] ERROR in app: Exception on /edit_profile [POST]
Traceback (most recent call last):
File "d:\microblog\venv\lib\site-packages\sqlalchemy\engine\base.py", line 1193, in _execute_context
context)
File "d:\microblog\venv\lib\site-packages\sqlalchemy\engine\default.py", line 509, in do_execute
cursor.execute(statement, parameters)
sqlite3.IntegrityError: UNIQUE constraint failed: user.username
...
...堆栈跟踪表明了bug是什么。目前应用程序允许用户更改用户名,且并不会验证新用户名是否跟系统中已有的其他用户名发生冲突。这个Error来自SQLAlchemy,它视图将新用户名写入数据库,但数据库拒绝了它,因为username列定义了unique=True。
重要的是要注意,呈现给用户的错误页面没有提供有关错误的大量信息,这很好!我们绝对不希望用户知道崩溃是由于数据库错误,或我正在使用数据库,又或在我的数据库中某些表和字段名称引起。所有这些信息都应该保留在内部。
有一些事情远非理想。上述错误页面很难看,跟应用程序布局不匹配。终端上的日志不断刷新,导致重要的堆栈跟踪信息被淹没,而我们不得不不断回顾它,以免遗漏。当然,我们有一个bug需要修复(fix)。我们将解决所有这些问题,但首先,来讨论下Flask的调试模式。
2. Debug模式(调试模式)
上述处理错误的方式对于在生产服务器上运行的系统来说非常有用。如果出现Error,用户会得到一个模糊的错误页面,并且错误的重要细节在服务器进程输出或日志文件中。
但在开发应用程序时,可启用调试模式,这是Flask在浏览器上直接运行一个友好调试器的模式。要激活调试模式,得先停止应用程序,然后设置以下环境变量:
(venv) D:\microblog>set FLASK_DEBUG=1在设置FLASK_DEBUG后,重新启动服务器。终端上的打印(输出)将与之前看到的略有不同:
(venv) D:\microblog>flask run
* Environment: production
WARNING: Do not use the development server in a production environment.
Use a production WSGI server instead.
* Debug mode: on
* Restarting with stat
* Debugger is active!
* Debugger PIN: 216-201-609
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)现在再次让应用程序崩溃,以便在浏览器中查看交互式调试器(the interactive debugger ): 
调试器允许我们展开每个堆栈帧并查看相应的源代码。还可以在任何框架上打开一个Python提示符,执行任何有效的Python表达式,如检查变量的值。
决不在生产服务器上以调试模式运行一个Flask应用程序 是非常重要的。调试器允许用户远程执行服务器中的代码,因此对于想侵入你的应用程序或服务器的恶意用户来说,这可能是一个意外礼物。作为额外的安全措施,在浏览器中运行的调试器开始锁定,并在第一次使用时将询问PIN号(flask run命令运行后可看到打印中的PIN号)
由于我们处于调试模式的主题,应该提到使用调试模式启用的第二个重要功能,即 重新加载器 reloader。这是一个非常有用的开发功能,可在修改源文件时自动重新启动应用程序。如果在调试模式下运行flask run命令,则可以在应用程序上运行,并且每次保存文件时,应用程序都将重新启动以获取新代码。
3. 自定义Error页面
Flask为应用程序提供了一种安装自己的错误页面的机制,如此,用户就不必看到默认、无聊的默认页面了。例如,为HTTP错误 404 和500定义自定义错误页面,这是两个最常见的错误页面。为其他错误定义页面的方式与此相同。
要声明自定义错误处理程序,得使用@errorhandler装饰器。在此,将错误处理程序放在一个新的app/errors.py模板中: app/errors.py:自定义错误处理程序
from flask import render_template
from app import app,db
@app.errorhandler(404)
def not_found_error(error):
return render_template('404.html'), 404
@app.errorhandler(500)
def internal_error(error):
db.session.rollback()
return render_template('500.html'), 500错误处理函数 与视图函数的工作方式非常相似。对于这俩个错误,将返回各自模板的内容。注意,两个函数都在模板后面返回第二个值,即错误代码编号。对于到目前为止,创建的所有视图函数,都不需要添加第二个返回值,因为默认值为200(成功响应的状态代码)。在这种情况下,这些是错误页面,所以希望响应的状态代码能够反映出来。
在数据库错误之后,可以调用500错误的错误处理程序,实际上是上面的用户名重复情况。为确保任何失败的数据库会话不会干扰模板触发的任何数据库访问,我们发出一个会话回滚(session rollback)。这将会使得会话重置为干净状态。
以下是404错误的模板: app/templates/404.html:找不到错误模板
{% extends "base.html" %}
{% block content %}
<h1>File Not Found</h1>
<p>
<a href="{{ url_for('index') }}">Back</a>
</p>
{% endblock %}这是500错误的模板: app/templates/500.html:内部服务器错误模板
{% extends "base.html" %}
{% block content %}
<h1>An unexpected error has occurred</h1>
<p>The administrator has been notified. Sorry for the inconvenience!</p>
<p>
<a href="{{ url_for('index') }}">Back</a>
</p>
{% endblock %}两个模板都继承自base.html,因此错误页面具有与应用程序的常规页面相同的外观。
要使用Flask注册这些错误处理程序,需要在创建应用程序实例后导入新的app/errors.py模板:
app/*init*.py:导入错误处理程序
#...
from app import routes,models,errors如果在终端会话中设置FLASK_DEBUG=0,然后再次触发重复的用户错误,将看到一个稍微友好的错误页面。
(venv) D:\microblog>set FLASK_DEBUG=0
(venv) D:\microblog>flask run
* Environment: production
WARNING: Do not use the development server in a production environment.
Use a production WSGI server instead.
* Debug mode: off
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
[2018-08-13 17:39:21,022] ERROR in app: Exception on /edit_profile [POST]
Traceback (most recent call last):
File "d:\microblog\venv\lib\site-packages\sqlalchemy\engine\base.py", line 1193, in _execute_context
context)
File "d:\microblog\venv\lib\site-packages\sqlalchemy\engine\default.py", line 509, in do_execute
cursor.execute(statement, parameters)
sqlite3.IntegrityError: UNIQUE constraint failed: user.username
4. 日志(log)写到文件中
通过电子邮件接收错误虽然很好,但有时这还不够。有些失败条件既不是Python异常,也不是主要问题,但它们在调试时,也是有足够用处的。因此,为应用程序维护一个日志文件。
为了启用另一个基于文件类型RotatingFileHandler的日志记录器,需要以和电子邮件日志记录器类似的方式将其附加到应用程序的logger对象中。
app/*init*.py:电子邮件配置
# ...
from logging.handlers import RotatingFileHandler
import os
# ...
if not app.debug:
# ...
if not os.path.exists('logs'):
os.mkdir('logs')
file_handler = RotatingFileHandler('logs/microblog.log', maxBytes=10240,
backupCount=10)
file_handler.setFormatter(logging.Formatter(
'%(asctime)s %(levelname)s: %(message)s [in %(pathname)s:%(lineno)d]'))
file_handler.setLevel(logging.INFO)
app.logger.addHandler(file_handler)
app.logger.setLevel(logging.INFO)
app.logger.info('Microblog startup')在logs目录中写入带有名称microblog.log的日志文件,如果它尚不存在,那么将创建这个日志文件。
这个RotatingFileHandler类很棒,因为它可切割、清理日志文件,以确保日志文件在应用程序运行很长一段时间也不会变得太大。在这种情况下,将日志文件大小限制为10kb,并且将最后10个日志文件保留为备份。
这个logging.Formatter类提供自定义格式的日志消息。由于这些消息正在写入到一个文件,我们希望它们可存储尽可能多的信息。所以我们使用的格式包括 时间戳、日志记录级别、消息、日志来源的源代码文件、行号。
为使日志记录更有用,还将应用程序、日志记录级别降低到INFO。如果不熟悉日志记录类别,它们分别是DEBUG、INFO、WARNING、ERROR、CRITICAL(按严重程度递增)
日志文件第一个有趣的用途是 服务器每次启动时都会在日志中写入一行。当这个应用程序在生产服务器上运行时,这些日志数据将告诉我们服务器何时重新启动过。
5. 修复重复的用户名bug
利用用户名重复这个BUG很久了,接下来将展示如何修复它。
应该还记得,RegistrationForm已实现了对用户名的验证,但是编辑表单的要求略有不同。在注册过程中,我们需要确保在表单中输入的用户名不存在于数据库中。在编辑个人资料表单中,我们必须执行相同的检查,但有一个例外。如果用户保存原有用户名不变,则验证应该允许,因为该用户名已分配给该用户。下面将展示如何为这个表单实现用户名验证:
app/forms.py:在编辑个人资料表单中验证用户名
class EditProfileForm(FlaskForm):
username = StringField('Username', validators=[DataRequired()])
about_me = TextAreaField('About me', validators=[Length(min=0, max=140)])
submit = SubmitField('Submit')
#验证用户名
def __init__(self, original_username, *args, **kwargs):
super(EditProfileForm, self).__init__(*args, **kwargs)
self.original_username = original_username
def validate_username(self, username):
if username.data != self.original_username:
user = User.query.filter_by(username=self.username.data).first()
if user is not None:
raise ValidationError('Please use a different username.')上述实现使用了一个自定义的验证方法,有一个重载的构造函数接受原始用户名作为参数。这个用户名保存为实例变量,并在validate_username()方法中进行检查。如果在表单中输入的用户名与原始用户名相同,那么就没必要检查数据库是否有重复了。
要使用这个新验证方法,还需要在对应的视图函数中添加原始用户名到表单的username参数中:
app/routes.py:在编辑个人资料表单中验证用户名
#...
@app.route('/edit_profile', methods=['GET', 'POST'])
@login_required
def edit_profile():
form = EditProfileForm(current_user.username)
#...现在修复了这个bug,并在大多数情况下,在编辑个人资料表单中出现用户名重复的提交将被友好地阻止。不过这不是一个完美的解决方案,因为当两个或多个进程同时访问数据库时,它可能不起作用。在这种情形下,竞争条件可能导致验证通过,但稍后当重命名时,数据库已经被另一个进程更改,并且无法重命名用户。除了非常繁忙的具有大量服务器进程的应用程序之外,这种情况不太可能发生,所以现在我们不用为此担心。
flask run运行程序,再次重现错误,查看新表单验证方法如何阻止这个bug。 
尝试更改不重名的username,效果:图略
查看数据库,看是否成功更改:
(venv) D:\microblog>sqlite3 app.db
SQLite version 3.16.2 2017-01-06 16:32:41
Enter ".help" for usage hints.
sqlite> select * from user;
1|susan2018|susan@example.com|pbkdf2:sha256:50000$OONOkVyy$8d008c6647ab95a5793cf60bf57eaa3bb1123d6e5b3135c5cc5e42e02eddae32|I rename my name.|2018-08-14 09:09:35.986028
2|belen|belen@example.com|pbkdf2:sha256:50000$PEDt5NxS$cf6c958c97b6ad28d9495d138cb5a310f6f2389534b0cafa3002dd3cec9af9d1|学 习Flask超级教程,Python Web开发学习,坚持!|2018-08-13 03:54:02.884780
sqlite> .quit目前为止,项目结构
microblog/
app/
templates/
_post.html
404.html
500.html
base.html
edit_profile.html
index.html
login.html
register.html
user.html
__init__.py
errors.py
forms.py
models.py
routes.py
logs/
microblog.log
migrations/
venv/
app.db
config.py
microblog.py参考 https://blog.miguelgrinberg.com/post/the-flask-mega-tutorial-part-vii-error-handling
13-flask博客项目实战八之关注功能
这章将学习如何实现类似于Twitter和其他社交网络的“粉丝”或“关注”,比如关注你。
接下来,将更多介绍应用程序的数据库。让用户能够轻松选择Ta们想要关注的其他用户。因此,将扩展数据库,以便跟踪谁在关注(粉)谁。
1. 重访数据库关系
我想每一个用户维护一个“关注”和“关注者”列表。不幸的是,关系数据库没有我能用于这些列表的列表类型,所有都有记录、这些记录之间的关系。
数据库中有一个表示用户的表,所以剩下的是提出可以为关注、关注者链接建模的正确关系类型。现在是学习基本数据库关系类型的好时机:
1.1. 一对多
使用过一对多关系,下方就是此关系的图表:一个用户可以有多个帖子 
通过这个关系连接的两个实体分别是 用户、帖子。一个用户有很多篇帖子,每个帖子有一个用户(作者)。在数据库中,这个关系在多侧使用外键。在上述关系中,外键user_id字段添加到posts表中。这个字段将每个帖子连接到user表中其作者的记录。
明显地,user_id字段提供了对给定帖子的作者的直接访问,但反过来呢?为使得关系有用,我们应该可以获得给定用户所编写的帖子列表。posts表中user_id字段也足以回答此问题,因为数据库中具有允许有效查询的索引,如 【检索user_id为X的所有帖子】
1.2. 多对多
多对多关系有点复杂。例如,考虑一个拥有students和teachers的数据库,可以说一个学生有很多个老师,一个老师有很多个学生。这就像来自两端的两个重叠的一对多关系。
对于这种类型的关系,我们应该能够查询到数据库,并取得教授给定学生的教师列表、教师班级的学生列表。这在关系数据库中表示实际上并不重要,因为无法通过向现有表添加外键来完成。
多对多关系的表示需要使用称为 关联表 的辅助表。下方是数据库如何查找学生和教师的案列: 
虽然一开始可能看起来不太明显,但是具有两个外键的关联表 能够有效地回答关于多对多关系的所有查询。
1.3. 多对一、一对一
多对一关系,类似于一对多关系。不同之处在于从“多”侧看这种关系。
一对一关系是一对多关系的特殊情况。表示是类似的,但是得向数据库添加约束以防止“多”侧具有多个链接。虽然在某些情况下,这种关系很有用,但并不像其他关系类型常见。
2. 表示粉丝
通过上述关系类型的学习,很容易确定跟踪关注者的正确数据模型是多对多关系。因为一个用户可以关注很多用户,而一个用户也可以被很多用户所关注。在学生、教师的案列中,我们通过多对多关系关联这两个实体。但在关注案列下,我有用户关注其他用户,所以只有用户。那么多对多关系的第二个实体是什么?
关系的第二个实体也是用户。将类的实例链接到同一个类的其他实例的关系 称为 自引用关系,这将是我们在此所拥有的。
下方是跟踪关注者的自引用 多对多关系的图表: 
followers表是关系的关联表。表中外键都指向user表中的行,因为它将用户链接到用户。这个表中每一个记录表示关注者用户、关注用户之间的一个链接。如同学生、教师的案列一样,像这样的设置允许数据库回答有关我们将要解决的 关注、关注用户的所有问题。
3. 用数据库模型表示
首先,在数据库中添加关注者 followers,下方是followers关联表: app/models.py:关注者关联表
#...
from flask_login import UserMixin
#关注者关联表
followers = db.Table(
'followers',
db.Column('follower_id', db.Integer, db.ForeignKey('user.id')),
db.Column('followed_id', db.Integer, db.ForeignKey('user.id'))
)
class User(UserMixin, db.Model):
#...上述代码是上一节【跟踪关注者的自引用 多对多关系的图表】的的直接翻译了。不过,注意,这里没有声明这个表为模型,即如user表、post表那样。由于这是一个除了外键而没有其他数据的辅助表,因此在没有关联模型类的情况下创建了这个表。
现在,可在user表中声明多对多关系: app/models.py:多对多 关注者 关系
#...
class User(UserMixin, db.Model):
#...
last_seen = db.Column(db.DateTime, default=datetime.utcnow)
followed = db.relationship(
'User',
secondary=followers,
primaryjoin=(followers.c.follower_id==id),
secondaryjoin=(followers.c.followed_id==id),
backref=db.backref('followers', lazy='dynamic'),
lazy='dynamic'
)
def __repr__(self):
return '<User {}>'.format(self.username)
#...这个关系的建立并非易事。如同我们为post表 一对多关系那样,正使用 db.relationship()函数进行定义模型类中的关系。这个关系将User实例 链接到其他User实例,因此作为约定,假设通过此关系链接到一对用户,左侧用户 关注 右侧用户。我们在左侧用户中定义了 followed 的关系,因为当我们从左侧查询这个关系时,将得到已关注的用户列表(即 右侧用户)。下方逐个检查db.relationship()的所有参数:
User是关系的右侧实体(左侧是父类)。由于这是一种自引用关系,我必须在两边使用相同的类。secondary配置用于这个关系的关联表,就是在这个类上定义的关联表followers。primaryjoin指定了左侧实体(关注者)与关联表链接的条件。关系左侧的连接条件是与关联表中follower_id字段匹配的用户ID。follwer.c.follower_id表达式引用了关联表中follower_id列。secondaryjoin指定了右侧实体(被关注者)与关联表链接的条件。这个条件与primaryjoin类似,唯一不同的是:现在使用的followed_id,它是关联表中的另一个外键。backref定义如何右侧实体访问这个关系。从左侧开始,关系被名称为followed,因此右侧将使用名称followers来表示链接到右侧目标用户的所有左侧用户。附加lazy参数表示这个查询的执行模式,设置为dynamic模式的查询在特定请求之前不会运行,这也是我们设置帖子的一对多关系。lazy类似于同名参数backref,但这个适用于左侧查询而不是右侧。
如果上述很难理解,不必担心。接下来将会展示如何利用这些关系来执行查询,一切将变得清晰。
数据库的改变 需要记录在 新的数据库迁移中:
(venv) D:\microblog>flask db migrate -m "followers"
[2018-08-15 15:25:39,889] INFO in __init__: Microblog startup
INFO [alembic.runtime.migration] Context impl SQLiteImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [alembic.autogenerate.compare] Detected added table 'followers'
Generating D:\microblog\migrations\versions\65b4b5c357fa_followers.py ... done
(venv) D:\microblog>flask db upgrade
[2018-08-15 15:26:03,154] INFO in __init__: Microblog startup
INFO [alembic.runtime.migration] Context impl SQLiteImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [alembic.runtime.migration] Running upgrade 00cd8a8ea68a -> 65b4b5c357fa, followers4. 关注和取消关注
由于SQLAlchemy ORM,一个用户关注另一用户 的行为 能被以followed 关系如同是一个列表一样 记录在数据库中,例如,假如我有两个用户存储在 user1 和 user2变量中,我能够用这个简单语句表示 第一个用户关注第二个用户:
user1.followed.append(user2)而停止关注这个用户,可以这样做:
user1.followed.remove(user2)尽管关注、取消关注 很容易,但我们希望在代码中提升可重用性,因此我们不会在代码中使用 “appends”、“removes”。代替的方法是,我们将在User模型中实现“follow”和“unfollow”方法。最后是将应用程序逻辑从视图函数移到模型或其他辅助类或模块中,因为正如在本章看到的,这让单元测试会变得更容易。
下方User模型中添加、删除关系的更改: app/models.py:添加、删除关注者
#...
class User(UserMixin, db.Model):
#...
def avatar(self, size):
digest = md5(self.email.lower().encode('utf-8')).hexdigest()
return 'https://www.gravatar.com/avatar/{}?d=identicon&s={}'.format(digest, size)
def follow(self, user):
if not self.is_following(user):
self.followed.append(user)
def unfollow(self, user):
if self.is_following(user):
self.followed.remove(user)
def is_following(self, user):
return self.followed.filter(followers.c.followed_id==user.id).count()>0
#...follow()、unfollow()方法用了正如上所展示的关系对象的append()、remove()方法,但是在它们接触这个关系之前,它们用了 is_following()辅助方法以确保请求动作是有道理的。例如,假如要求 user1 关注user2,但事实证明在数据库中已经存在这个关注关系,就不必重复了。相同的逻辑同样运用到 取消关注。
is_following()方法在followed关系中发出一个查询去检查两个用户是否已存在链接。在之前看到 使用SQLAlchemy的filter_by()方法去查询对象,例如 查找给定username的用户。在这用到的filter()方法是类似的,但是低水平,因为它能包含任意过滤条件,不像filter_by()只能检查与常量值的相等性。在is_following()中我们正在使用的条件 查找关联表中的项目,左侧外键设置为self 用户,右侧设置为 user参数。查询以一个count()方法终止,该方法返回结果数。这个查询结果将是0 或1,因此检查计数为1 或大于0实际上是等效的。过去使用的前提查询终止符是all()、first()。
5. 获取已关注用户的帖子
对数据库中的关注者的支持几乎已经完成,但实际上还缺少一个重要的功能。在应用程序的index页面,将显示已登录用户所关注的其他所有用户的帖子,因此,我们需要提供一个返回这些帖子的数据库查询。
最明显解决方案是 运行一个返回已关注用户列表的查询,正如我们已知道的,它就是 user.followed.all()。接着,对这些返回的每个用户,我们运行查询取得帖子。一旦我们有了帖子,就将它们合并到一个列表,并按日期对它们进行排序。听起来是这样,其实不是!
这种方法有几个问题。假如一个用户关注了1000人,会发送什么?那么我得执行1000此数据库查询来收集所有帖子。接着需要合并、排序内存中的1000个列表。第二个问题,考虑到应用程序的主页最终将实现分页,因此它不会显示所有可用帖子,仅是前几个,如果需要,可用一个链接去取得更多。第三个问题,如果要按日期排序显示帖子,如何知道哪些用户帖子才是所有用户中最新的?除非我得到所有帖子并先排序。这实际上是一个不能很好扩展的糟糕解决方案。
实际上并没有办法避免博客帖子的合并、排序,但在应用程序中执行会导致一个非常低效的过程。这类工作是关系数据库最擅长的。数据库具有索引,允许它以更有效的方式执行查询、排序。因此,我们真正想要的是提出一个简单的数据库查询,它定义了我们想要取得的信息,然后让数据库找出如何以最有效的方式提取信息。
下方就是这个查询: app/models.py:已关注用户的帖子的查询
#...
class User(UserMixin, db.Model):
#...
def is_following(self, user):
return self.followed.filter(followers.c.followed_id==user.id).count()>0
def followed_posts(self):
return Post.query.join(
followers, (followers.c.followed_id==Post.user_id)).filter(
followers.c.follower_id==self.id).order_by(
Post.timestamp.desc())
#...这是在这个应用程序中使用的最复杂的查询了。这个查询结构有3个主要部分 join()、filter()、order_by(),都是SQLAlchemy中查询对象的方法。
5.1. 联合查询
要理解 join 操作的作用,先看一个例子。假设我有一个User表,包含以下内容: 
简单起见,我们不显示 用户模型中的所有字段,只显示对这个查询的重要字段。
假设 followers 关联表 表示用户john正在关注用户susan和david,用户susan正在关注用户mary,用户mary正在关注david。表示这个内容的数据是: 
最后,posts表 包含每个用户的一条帖子: 
这个表还省略了一些不属于本讨论范围的字段。
这是我为这个查询再次定义的join():
Post.query.join(followers, (followers.c.followed_id == Post.user_id))上述代码正在posts表上调用join 操作。第一个参数是关注者关联表;第二个参数是连接条件。我希望数据库创建一个临时表,此表结合了posts表、followers表的数据。这个数据将根据我作为参数传递的条件进行合并。
使用的条件是followers表的followed_id字段 必须等于 posts表的user_id字段。要执行此合并,数据库将从posts表(join 的左侧)获取每个记录,并附加followers表(join 的右侧)中匹配条件的所有记录。如果followers表中有多个记录符合条件,则每个记录条目将重复。如果对于给定的帖子在followers表没有匹配,那么这个帖子记录不会join操作结果中。
使用上述定义的示例数据,join操作的结果是: 
注意,在所有情况下,user_id和followed_id列是如何相等的,这是因为连接条件。来自用户john的帖子没有出现在上述连接表中,是因为被关注者中没有包含用户john,换句话说,没有任何人关注john。而来自用户david的帖子出现了两次,因为这个用户有个关注者。
虽然创建了join操作,但暂时并未得到想要的结果。请继续,这只是更大查询的一部分。
5.2. 过滤
join操作给我一个所有被关注用户的帖子的列表,远超出我真正想要的那部分数据。我只对这个列表的一个子集感兴趣,即某个用户关注的用户们的帖子。因此,我需要调用filter()来去掉不需要的数据。
下方是查询的过滤部分:
filter(followers.c.follower_id == self.id)由于这个查询是位于User类中的方法,因此self.id 表达式引用了我感兴趣的用户的用户ID。filter()选择join表中follower_id等于这个ID的行,换句话说,我只保留follower是这个用户的数据。
假设我感兴趣的用户是 john,其 id 字段设置为1,下方是join表在过滤后的样子: 
这些才是我想要的帖子。
记住,查询是从Post类发出的,所以即使我最终得到了由数据库创建的一个临时表来作为查询的一部分,但结果是包含在此临时表中的帖子,并没有额外的列是由join操作添加的。
5.3. 排序
查询流程的最后一步是 对结果就行排序。这部分的查询语句如下:
order_by(Post.timestamp.desc())在此,希望结果是按帖子的时间戳字段按降序排序的。通过这个排序,第一个结果将是最新的博客帖子。
5.4. 结合自己和关注者的帖子
在followed_posts()函数中使用的查询非常有用,但有一限制。人们希望看到自己的帖子也包含在Ta所关注的用户帖子的时间线中,不过这个查询目前还未建立。
有两种方法可扩展此查询以包含用户自己的帖子。最直接的方法是 保持查询变,但要确保所有用户都关注自己。如果你是自己的关注者,那么上面显示的查询将会找到你自己的帖子,以及你关注的所有人帖子。这种方法的缺点是它会影响关于关注者的统计数据。所有的关注者数量都会被加1,所以必须在显示之前进行调整。第二个方法是通过创建第二个查询,返回用户自己的帖子,然后使用 union 运算符 将这两个查询合并为一个查询。
在考虑了这两个选项后,决定选择第二个方法。下方将看到followed_posts()扩展后的功能,通过一个 union 包含用户自己的帖子:修改代码 app/models.py:加上用户自己的帖子
#...
#...
def followed_posts(self):
followed = Post.query.join(followers, (followers.c.followed_id == Post.user_id)).filter(followers.c.follower_id == self.id)
own = Post.query.filter_by(user_id=self.id)
return followed.union(own).order_by(Post.timestamp.desc())
#...在排序之前,注意followed 和 own 查询结果集是如何合并为一个的。
6. 对User模型进行单元测试
虽然我不担心建立的这个“复杂的”关注功能的实现,但我认为它并非微不足道。但当编码重要代码时,担心的是确保这部分代码将来继续工作,因为在应用程序的不同部分进行了修改。确保已编写代码将来继续工作的最佳方法是创建一套自动化测试,每次更改时都可以重新运行。
Python包含一个非常有用的 unittest包,可轻松编写、执行单元测试。在 tests.py模块中为User类存在的方法编写一些单元测试: microblog/tests.py:用户模型单元测试
from datetime import datetime,timedelta
import unittest
from app import app,db
from app.models import User,Post
class UserModelCase(unittest.TestCase):
def setUp(self):
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite://'
db.create_all()
def tearDown(self):
db.session.remove()
db.drop_all()
def test_password_hashing(self):
u = User(username='susan2018')
u.set_password('cat')
self.assertFalse(u.check_password('dog'))
self.assertTrue(u.check_password('cat'))
def test_avatar(self):
u = User(username='john', email='john@example.com')
self.assertEqual(u.avatar(128), ('https://www.gravatar.com/avatar'
'/d4c74594d841139328695756648b6bd6'
'?d=identicon&s=128'))
def test_follow(self):
u1 = User(username='john', email='john@example.com')
u2 = User(username='susan', email='susan@example.com')
db.session.add(u1)
db.session.add(u2)
db.session.commit()
self.assertEqual(u1.followed.all(), [])
self.assertEqual(u2.followers.all(), [])
u1.follow(u2)
db.session.commit()
self.assertTrue(u1.is_following(u2))
self.assertEqual(u1.followed.count(), 1)
self.assertEqual(u1.followed.first().username, 'susan')
self.assertEqual(u2.followers.count(), 1)
self.assertEqual(u2.followers.first().username, 'john')
u1.unfollow(u2)
db.session.commit()
self.assertFalse(u1.is_following(u2))
self.assertEqual(u1.followed.count(), 0)
self.assertEqual(u2.followers.count(), 0)
def test_follow_posts(self):
#create four users
u1 = User(username='john', email='john@example.com')
u2 = User(username='susan', email='susan@example.com')
u3 = User(username='mary', email='mary@example.com')
u4 = User(username='david', email='david@example.com')
db.session.add_all([u1, u2, u3, u4])
#create four posts
now = datetime.utcnow()
p1 = Post(body="post from john", author=u1, timestamp=now+timedelta(seconds=1))
p2 = Post(body="post from susan", author=u2, timestamp=now+timedelta(seconds=4))
p3 = Post(body="post from mary", author=u3, timestamp=now+timedelta(seconds=3))
p4 = Post(body="post from david", author=u4, timestamp=now+timedelta(seconds=2))
db.session.add_all([p1, p2, p3, p4])
db.session.commit()
#setup the followers
u1.follow(u2)#john follows susan
u1.follow(u4)#john follows david
u2.follow(u3)#susan follows mary
u3.follow(u4)#mary follows david
db.session.commit()
#check the followed posts of each user
f1 = u1.followed_posts().all()
f2 = u2.followed_posts().all()
f3 = u3.followed_posts().all()
f4 = u4.followed_posts().all()
self.assertEqual(f1, [p2, p4, p1])
self.assertEqual(f2, [p2, p3])
self.assertEqual(f3, [p3, p4])
self.assertEqual(f4, [p4])
if __name__ == '__main__':
unittest.main(verbosity=2)上述添加了4个测试,用于在用户模型中执行密码哈希、用户头像、关注者功能。setUp()、tearDown()方法是特殊方法,分别用于单元测试框架之前、每次测试后执行。
在setUp()实现了一些小技巧,以防止单元测试使用我们用于开发的常规数据库。通过将应用程序配置更改为 sqlite:// ,在测试期间,让SQLAlchemy使用内存中的SQLite数据库。db.create_all()创建所有数据库表。这是从头开始创建数据库的快速方法,可用于测试。对于开发环境和生产环境的数据库结构管理,之前已展示过数据库迁移的方法。
下方命令可运行整个测试组件:
C:\Users\Administrator>d:
D:\>cd D:\microblog\venv\Scripts
D:\microblog\venv\Scripts>activate
(venv) D:\microblog\venv\Scripts>cd D:\microblog
(venv) D:\microblog>python tests.py
[2018-08-16 11:42:36,534] INFO in __init__: Microblog startup
test_avatar (__main__.UserModelCase) ... ok
test_follow (__main__.UserModelCase) ... ok
test_follow_posts (__main__.UserModelCase) ... ok
test_password_hashing (__main__.UserModelCase) ... ok
----------------------------------------------------------------------
Ran 4 tests in 0.211s
OK
(venv) D:\microblog>从现在开始,每次对应用程序进行更改时,都可以重新运行测试以确保正在测试的功能不受到影响。此外,每次向应用程序添加另一个功能时,都应为其编写单元测试。
7. 将关注功能集成到应用程序
数据库、模型中的关注功能已实现,但还没有将它纳入到应用程序中,因此现在添加它。这个操作没有挑战,因为都是基于之前学到的概念、知识。
在应用程序中添加两个新路由,以关注、取消关注一个用户:
app/routes.py:关注、取消关注用户的路由
上述代码较简单,不过要注意当中的 所有错误检查,以防止意外问题,并在发生问题时向用户提供有用的消息。
现在有了视图函数,就可以从应用程序中的页面链接到它们了。在每个用户的个人资料页面中添加链接以关注、取消关注用户:
app/rtemplates/user.html:在用户个人资料页面中添加 关注、取消关注的链接
...
{% if user == current_user %}
<p>
<a href="{{ url_for('edit_profile') }}">Edit your profile</a>
</p>
{% elif not current_user.is_following(user) %}
<p>
<a href="{{ url_for('follow', username=user.username) }}">Follow</a>
</p>
{% else %}
<p>
<a href="{{ url_for('unfollow', username=user.username) }}">Unfollow</a>
</p>
{% endif %}
...对用户个人资料页面更改:一是 在最近访问的时间戳下添加一行,以显示该用户拥有多少关注者和关注用户。二是当查看自己的个人资料页时,出现的“Edit”链接,可能会变成下方3种链接之一:
- 如果用户正在查看自己的个人资料页,那么“
Edit”链接跟以前一样显示; - 如果用户正在查看当前未关注的用户,则会显示“
Follow”链接; - 如果用户正在查看当前关注的用户,则会显示“
Unfollow”链接。
此时,运行应用程序,创建一些用户并测试 关注、取消关注用户的功能。 唯一需要记住的是,键入要关注 或取消关注的用户的个人资料页面的URL,因为目前无法查看用户列表。例如,如果要关注 susan,则可在浏览器地址栏输入:http://localhost:5000/user/susan,就能访问该用户的个人资料页。确保在测试关注、取消关注时,检查关注、关注者的数量变化情况。
(venv) D:\microblog>flask run
* Environment: production
WARNING: Do not use the development server in a production environment.
Use a production WSGI server instead.
* Debug mode: off
[2018-08-16 14:02:45,152] INFO in __init__: Microblog startup
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
127.0.0.1 - - [16/Aug/2018 14:02:54] "GET /user/susan2018 HTTP/1.1" 200 -目前登录用户为susan2018,输入http://127.0.0.1:5000/user/belen,页面中显示“Follow”链接,点击它,注意页面的变化。 

再注册用户john、mary、david,邮箱分别为用户名加@example.com,密码都为123456。 之前有两个用户susan(后改名susan2018,密码cat)、belen 密码Abc123456。 分别用这些用户登录、关注某些用户。进入数据库查看:
(venv) D:\microblog>sqlite3 app.db
SQLite version 3.16.2 2017-01-06 16:32:41
Enter ".help" for usage hints.
sqlite> select * from user;
1|susan2018|susan@example.com|pbkdf2:sha256:50000$OONOkVyy$8d008c6647ab95a5793cf60bf57eaa3bb1123d6e5b3135c5cc5e42e02eddae32|I rename my name.|2018-08-16 06:16:13.474911
2|belen|belen@example.com|pbkdf2:sha256:50000$PEDt5NxS$cf6c958c97b6ad28d9495d138cb5a310f6f2389534b0cafa3002dd3cec9af9d1|学习Flask超级教程,Python Web开发学习,坚持!|2018-08-16 06:15:38.892932
3|john|john@example.com|pbkdf2:sha256:50000$vdxx4ipx$32ccbde4bc984d459c5a99935adb8c1ce8fc5c0d3e5d7f442815e5005d1a80a4||2018-08-16 06:11:21.665502
4|mary|mary@example.com|pbkdf2:sha256:50000$8q3qPO4V$040967e4481a4882d5277a52b01902b54f3af38736336c08852f2fbae7df61a6||2018-08-16 06:12:21.538626
5|david|david@example.com|pbkdf2:sha256:50000$OhRhtXc2$c03c098ee789ef9229e2f99676f173a30e876f047991744d05f11d6afe296a31||2018-08-16 06:12:50.972967
sqlite> select * from followers;
1|2
2|3
2|4
1|5
1|4
sqlite> .quit
(venv) D:\microblog>followers表 第一列为 follower_id,第二列为 followed_id。上述含义: 1 susan2018关注了 2 belen、5 david、4 mary 2 belen 关注了 3 john、4 mary
应该在应用程序 /index页面中显示所有关注帖子的列表,但由于目前用户还不能编写博客帖子(此功能还未完成)。因此,将此推迟更改,直到该功能到位。
目前为止,项目结构:
microblog/
app/
templates/
_post.html
404.html
500.html
base.html
edit_profile.html
index.html
login.html
register.html
user.html
__init__.py
errors.py
forms.py
models.py
routes.py
logs/
microblog.log
migrations/
venv/
app.db
config.py
microblog.py
tests.py参考 https://blog.miguelgrinberg.com/post/the-flask-mega-tutorial-part-viii-followers
14-flask博客项目实战九之分页功能
这章将学习如何对数据库中条目列表进行分页。
在上一节,进行了一些必要的数据库更改,以支持社交网络大受欢迎的“关注”功能。有了这个功能,我们准备删除最后一块脚手架,那就是一开始放置的“假”帖子。在这一章,应用程序将开始接受用户的博客帖子,并在 /index页面和个人资料页面展示它们。
1. 提交博客帖子
主页需要一个 表单,用户在此可以写新帖子。首先,建立一个表单类: app/forms.py:博客提交表单
#...
class PostForm(FlaskForm):
post = TextAreaField('Say something', validators=[DataRequired(), Length(min=1, max=140)])
submit = SubmitField('Submit')接着,将上述表单添加到应用程序主页的模板中: app/templates/index.html:index模板中帖子提交表单
{% extends "base.html" %}
{% block content %}
<h1>Hello,{{ current_user.username }}!</h1>
<form action="" method="post">
{{ form.hidden_tag() }}
<p>
{{ form.post.label }}<br>
{{ form.post(cols=32, rows=4) }}<br>
{% for error in form.post.errors %}
<span style="color:red;">[{{ error }}]</span>
{% endfor %}
</p>
<p>{{ form.submit() }}</p>
</form>
{% for post in posts %}
<p>
{{ post.author.username }} says: <b>{{ post.body }}</b>
</p>
{% endfor %}
{% endblock %}这个模板的更改与以前的表单处理方式类似。
最后,在视图函数 index() 中添加上述表单的创建和处理:修改代码 app/routes.py:在视图函数中的帖子提交表单
#...
from app.forms import PostForm
from app.models import Post
#...
@app.route('/', methods=['GET', 'POST'])
@app.route('/index', methods=['GET', 'POST'])
@login_required
def index():
form = PostForm()
if form.validate_on_submit():
post = Post(body=form.post.data, author=current_user)
db.session.add(post)
db.session.commit()
flash('Your post is now live!')
return redirect(url_for('index'))
posts = [
{
'author': {'username': 'John'},
'body': 'Beautiful day in Portland!'
},
{
'author': {'username': 'Susan'},
'body': 'The Avengers movie was so cool!'
}
]
return render_template("index.html", title='Home Page', form=form,
posts=posts)
#...逐一查看视图函数中的更改:
- 导入
Post、PostForm类; - 除
GET请求外,关联到两个路由的视图函数index()都接受POST请求,因为这个视图函数现在将接收表单数据; - 表单处理逻辑将一个
新Post记录插入数据库; - 模板接收
form对象作为一个附加参数,以便它呈现文本字段。
在继续之前,我想提一些处理Web表单相关的重要事项。注意,在我处理表单数据后,通过发出一个重定向到主页来结束请求。我可以轻松地跳过重定向,并允许函数继续向下进入模板渲染部分,因为这已经是index()视图函数的功能了。
所以,为什么要重定向?标准做法是通过重定向来响应一个由Web表单提交生成的POST请求。这有助于缓解一个在Web浏览器如何实现刷新命令的烦恼。当点击 刷新键时,所有Web浏览器都会重新发出最后一个请求。如果带有表单提交的POST请求返回常规响应,那么刷新将重新提交表单。因为这是意料之外的,浏览器将要求用户确认重复提交,但大多数用户将无法理解浏览器询问的内容。但是,如果POST请求用重定向来回答请求,则浏览器现在指示发送一个GET请求以获取重定向中指示的页面,因此,现在最后一个请求不再是POST请求,刷新命令可以更可预测的方式工作。
这个简单的技巧称为:Post/Redirect/Get模式。当用户在提交Web表单后,无意中刷新页面时,它可以避免插入重复的帖子。
2. 显示博客帖子
应该记得,之前创建了一些虚假博客帖子,在主页上显示了很长时间了。这些虚拟对象在index()视图函数中显示创建为一个简单的Python列表:
posts = [
{
'author': {'username': 'John'},
'body': 'Beautiful day in Portland!'
},
{
'author': {'username': 'Susan'},
'body': 'The Avengers movie was so cool!'
}
]但是,现在User模型中我有followed_posts()方法,它返回给定用户想看的帖子的查询。所以,现在可用真正的帖子替换“假”帖子: app/routes.py:在主页显示真实的帖子
@app.route('/', methods=['GET', 'POST'])
@app.route('/index', methods=['GET', 'POST'])
@login_required
def index():
# ...
posts = current_user.followed_posts().all()
return render_template("index.html", title='Home Page', form=form,
posts=posts)User类的followed_posts()方法返回一个SQLAlchemy查询对象,这个对象配置为 从数据库中获取用户感兴趣的帖子。在这个查询中调用all()方法会触发其执行,返回值为一个所有结果集的列表。所以最终得到的结构 跟之前使用的“假”帖子非常相似。正因如此,模板就无须更改了。 flask run 命令运行程序,效果:
C:\Users\Administrator>d:
D:\>cd D:\microblog\venv\Scripts
D:\microblog\venv\Scripts>activate
(venv) D:\microblog\venv\Scripts>cd D:\microblog
(venv) D:\microblog>flask run
* Environment: production
WARNING: Do not use the development server in a production environment.
Use a production WSGI server instead.
* Debug mode: off
[2018-08-17 09:59:26,504] INFO in __init__: Microblog startup
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
127.0.0.1 - - [17/Aug/2018 09:59:36] "GET /index HTTP/1.1" 200 -补充 提交帖子后的效果。(导航 Explore链接是后续添加的),图略
数据库查看刚才刚才添加的帖子:
(venv) D:\microblog>sqlite3 app.db
SQLite version 3.16.2 2017-01-06 16:32:41
Enter ".help" for usage hints.
sqlite> select * from post;
1|哈哈哈 测试一下 我是susan2018|2018-08-17 02:03:36.912898|1
sqlite> .quit
(venv) D:\microblog>3. 轻松地找到用户和关注
如上述上一小节效果所示,应用程序不能方便地让用户找到其他用户、自己的帖子。事实上,目前为止还没有办法查看其他用户在哪里。接下来,将通过简单的更改解决这个问题。
创建一个新页面,称之为 “Explore”页面。这个页面像主页一样工作,但不会仅显示来自所关注用户的帖子,而是显示来自所有用户的全局帖子流。下方是新的 explore()视图函数: app/routes.py:
#...
def index():
#...
@app.route('/explore')
@login_required
def explore():
posts = Post.query.order_by(Post.timestamp.desc()).all()
return render_template('index.html', title='Explore', posts=posts)
#...可注意到,这个视图函数有些奇怪。render_template()调用引用了index.html模板,它是应用程序的主页使用的模板。由于这个页面 跟主页面非常相似,因此重用index.html模块。不过,与主页面有一个区别是 在/explore页面中不需要一个写博客帖子的表单,所以在这个视图函数中,没有在模板中调用 包含form的参数。
为了防止index.html模板在呈现不存在的Web表单时崩溃,将添加一个条件,只有在定义时才呈现表单(即传入表单参数后才会呈现): app/templates/index.html:让博客帖子提交表单 可选
{% extends "base.html" %}
{% block content %}
<h1>Hi, {{ current_user.username }}!</h1>
{% if form %}
<form action="" method="post">
...
</form>
{% endif %}
...
{% endblock %}还需在导航栏中添加指向这个新页面的链接: app/templates/base.html:
<a href="{{ url_for('index') }}">Home</a>
<a href="{{ url_for('explore') }}">Explore</a>_post.html子模板,用于在用户个人资料页面中呈现博客帖子。这是一个包含在用户个人资料页面模板中的小模板,是独立的,因此也可以从其他模板中引用。现在对它进行一些改进,即 将博客帖子作者的用户名显示为链接: app/templates/_post.html:在博客帖子中显示作者的链接
<table>
<tr valign="top">
<td><img src="{{ post.author.avatar(36) }}"></td>
<td>
<a href="{{ url_for('user', username=post.author.username) }}">{{ post.author.username }}</a> says:<br>{{ post.body }}
</td>
</tr>
</table>现在,就可以使用子模板在主页、/explore页面中呈现博客帖子: app/templates/index.html:使用博客帖子 子模板
...
{% for post in posts %}
{% include '_post.html' %}
{% endfor %}
...子模板需要一个存在的名为 post 的变量,才能完美地工作,这是在 index模板中 循环变量的命名方式。
通过上述这些微小的变化,应用程序的可用性得到显著改善。现在,用户可访问 /explore页 阅读来自未知用户的博客帖子,并根据这些帖子找到要关注的新用户,只需单击用户名就可访问 个人资料页面。
flask run 运行程序,登录susan2018、belen、john发几个帖子,效果: 
4. 博客帖子分页
现在应用程序看起来比以前更好,但是在主页显示所有关注的帖子很快将变成一个问题。如果用户有1000个关注帖子会怎么样?如果是100万呢?可以想象,管理如此庞大的帖子列表将很缓慢且效率低下。
为解决这个问题,我将对帖子列表进行分页。这意味着,最初将一次只显示有限数量的帖子,并包含用于浏览整个帖子列表的链接。Flask-SQLAlchemy本身支持使用paginate()查询方法进行分页。例如,如果想获得用户的前20个帖子,可以用如下代码替换all()终止查询:
>>>user.followed_posts().paginate(1,20,False).itemspaginate()方法可以在Flask_SQLAlchemy的任何查询对象上调用。它有3个参数:
- 页码,从1开始;
- 每页的项目数;
- 错误标志。若为
True,当请求超出范围的页面时,404错误将自动返回给客户端。若为False,超出范围的页面将返回一个空列表。paginate()方法的返回值是一个Pagination对象。这个对象的items属性包含所请求页面的项目列表。在Pagination对象中还有其他有用的东西,稍后讨论。
现在让我们考虑如何在index()视图函数实现分页。首先,在应用程序config.py中添加一个配置项,以确定每页显示多少个项目数。 microblog/config.py:每页配置的帖子
#...
class Config:
#...
ADMINS = ['your-email@example.com']
POSTS_PER_PAGE = 3这些应用程序范围内的 旋钮能改变配置文件中的行为,因为我能够去一个简单的地方做调整。在最终的应用程序中,当然会使用每页大于3个项目的数字,但是对于测试,使用小数字就有用了。
接下来,我需要决定如何将页码合并到应用程序的URL中。一种常见的方法是使用查询字符串参数来指定可选的页码,如果没有给出,就默认第1页。下方是一些示例网址,展示将如何实现这一点:
- 第1页,隐式:
http://localhost:5000/index - 第1页,显式:
http://localhost:5000/index?page=1 - 第3页:
http://localhost:5000/index?page=3要访问查询字符串中给出的参数,我可以使用Flask的request.args对象。在第5章中,实现了Flask-Login中可包含next查询字符串参数的用户登录URL。
下方将可以看到如何向/index、/explore视图函数中添加分页: app/routes.py:关注者关联表
#...
def index():
#...
page = request.args.get('page', 1, type=int)
posts = current_user.followed_posts().paginate(page, app.config['POSTS_PER_PAGE'], False)
return render_template('index.html', title='Home Page', form=form, posts=posts.items)
@app.route('/explore')
@login_required
def explore():
page = request.args.get('page', 1, type=int)
posts = Post.query.order_by(Post.timestamp.desc()).paginate(page, app.config['POSTS_PER_PAGE'], False)
return render_template('index.html', title='Explore', posts=posts.items)
#...通过上述更改,两个路由确定要显示的页码,可以是page查询字符串参数,或 默认值1,然后使用paginate()方法取得所需结果的页面。通过app.config对象的POSTS_PER_PAGE 配置项 决定了要访问页码的大小。
注意,这些更改很容易,以及 每次更改代码的影响程度如何。我正尝试编写应用程序的每个部分,而不对其他部分如何工作做任何假设,这使我能够编写更易于扩展和测试的模块化、健壮的应用程序,并且不太可能出现故障 或bug。
运行程序,测试上述所编写的分页支持。首先,确保3篇以上的帖子。这在 /explore页面很容易看到,这个页面显示所有用户的帖子。目前将只会看到最近的3篇帖子。若要查询下一个3篇帖子,可在浏览器地址栏输入:http://localhost:5000/explore?page=2
5. 页面导航
下一个更改是 在博客帖子列表底部添加链接,允许用户导航到下一页 或上一页。还记得 调用paginate()方法的返回值是一个Flask-SQLAlchemy的Pagination类的一个对象?目前为止,我们已经使用了这个对象的items属性,它包含为所选页面检索的项目列表。但是 这个对象还具有一些在构建分页链接时有用的前提属性:
has_next:如果当前页面后面至少还有一页,则为True;has_prev:如果在当前页面之前至少还有一页,则为True;next_num:下一页的页码;prev_num:上一页的页码。 通过上述4个属性,可生成下一个和上一个页面链接,并将它们传递给模板进行渲染: app/routes.py:下一页和上一页链接
#...
def index():
#...
page = request.args.get('page', 1, type=int)
posts = current_user.followed_posts().paginate(page, app.config['POSTS_PER_PAGE'], False)
next_url = url_for('index', page=posts.next_num) if posts.has_next else None
prev_url = url_for('index', page=posts.prev_num) if posts.has_prev else None
return render_template('index.html', title='Home Page', form=form, posts=posts.items, next_url=next_url, prev_url=prev_url)
@app.route('/explore')
@login_required
def explore():
page = request.args.get('page', 1, type=int)
posts = Post.query.order_by(Post.timestamp.desc()).paginate(page, app.config['POSTS_PER_PAGE'], False)
next_url = url_for('explore', page=posts.next_num) if posts.has_next else None
prev_url = url_for('explore', page=posts.prev_num) if posts.has_prev else None
return render_template('index.html', title='Explore', posts=posts.items, next_url=next_url, prev_url=prev_url)上述两个视图函数的next_url 和prev_url 只有在该方向上有页面时,才会设置为由url_for()返回的的一个URL。如果当前页面位于帖子集合的一端,则Pagination对象的has_next或has_prev属性将是False,并在这种情况下,该方向上的链接将被设置为None。
url_for()函数有一个有趣的方面(之前未讨论过)是 你能够向它添加任何关键字参数,如果这些参数的名字没有直接在URL中引用,那么Flask会将它们作为查询参数包含在URL中。
分页链接被设置在 index.html模板中,所以现在帖子列表的正下方渲染它们: app/templates/index.html:在模板中渲染分页链接
...
{% for post in posts %}
{% include '_post.html' %}
{% endfor %}
{% if prev_url %}
<a href="{{ prev_url }}">Newer posts</a>
{% endif %}
{% if next_url %}
<a href="{{ next_url }}">Older posts</a>
{% endif %}
...这个更改会在 /index页、/explore页上的帖子列表下添加链接。第一个链接标记为“Newer posts”,指向上一页(注意,显示帖子按最新排序,因此第一页是具有最新内容的页面)。第二个链接标记为“Older posts”,指向帖子的下一页。如果这两个链接中的任何一个是None,则通过条件从页面中省略它。
运行程序,效果: 
6. 在用户个人资料页面分页
/index 页面的更改现在已足够。但是,用户个人资料页面中还有一个帖子列表,其仅显示来自个人资料所有者的帖子。为了保持一致,应更改用户个人资料页面以匹配 /index页面的分页样式。
首先,更新用户个人资料的视图函数,其中仍然有一个“假”帖子的对象列表。 app/routes.py:用户个人资料页面视图中的分页
#...
@app.route('/user/<username>')
@login_required
def user(username):
user = User.query.filter_by(username=username).first_or_404()
page = request.args.get('page', 1, type=int)
posts = user.posts.order_by(Post.timestamp.desc()).paginate(page, app.config['POSTS_PER_PAGE'], False)
next_url = url_for('user', username=user.username, page=posts.next_num) if posts.has_next else None
prev_url = url_for('user', username=user.username, page=posts.prev_num) if posts.has_prev else None
return render_template('user.html', user=user, posts=posts.items, next_url=next_url, prev_url=prev_url)
#...为了取得用户的帖子列表,我利用了一个事实,即 user.posts 关系是一个通过SQLAlchemy</b已经建立的查询,它是在User模型中由db.relationship()定义的结果。我们接受这个查询,并添加一个order_by()子句,以便首先取得最新的帖子,然后像对 /index和 /explore页中那样完成分页。注意,url_for()函数生成的分页链接 需要额外的 username参数,因为它们指向用户个人资料页面,这个页面具有这个用户名作为URL的动态组件。
最后,对user.html模板的更改 与在/index页面上所做 的更改相同: app/templates/user.html:用户个人资料页面模板的分页链接
#...
{% for post in posts %}
{% include '_post.html' %}
{% endfor%}
{% if prev_url %}
<a href="{{ prev_url }}">Newer posts</a>
{% if next_url %}
<a href="{{ next_url }}">Older posts</a>
{% endif %}
{% endblock%}完成分页功能的实验后,可将POSTS_PER_PAGE配置项设置为更合理的值: microblog/config.py:每个页面配置 帖子
class Config(object):
# ...
POSTS_PER_PAGE = 25目前为止,项目结构
microblog/
app/
templates/
_post.html
404.html
500.html
base.html
edit_profile.html
index.html
login.html
register.html
user.html
__init__.py
errors.py
forms.py
models.py
routes.py
logs/
microblog.log
migrations/
venv/
app.db
config.py
microblog.py
tests.py参考 https://blog.miguelgrinberg.com/post/the-flask-mega-tutorial-part-ix-pagination
